【Transformers】 Tokenizer
Tokenizer
Tokenizer即分词器,主要任务是将文本输入转化为模型可以接受的输入,即数值索引。
不同的Tokenizer策略可以不同的结果,常用的策略有:word base(按照词进行分词),character base(按照单词进行分词),subword tokenization(按照subword进行分词)
Word-based
word base进行分词的话,有两种方式,一种是根据whitespace进行分割,一种是根据标点符号进行分割,然后再做数字的映射。
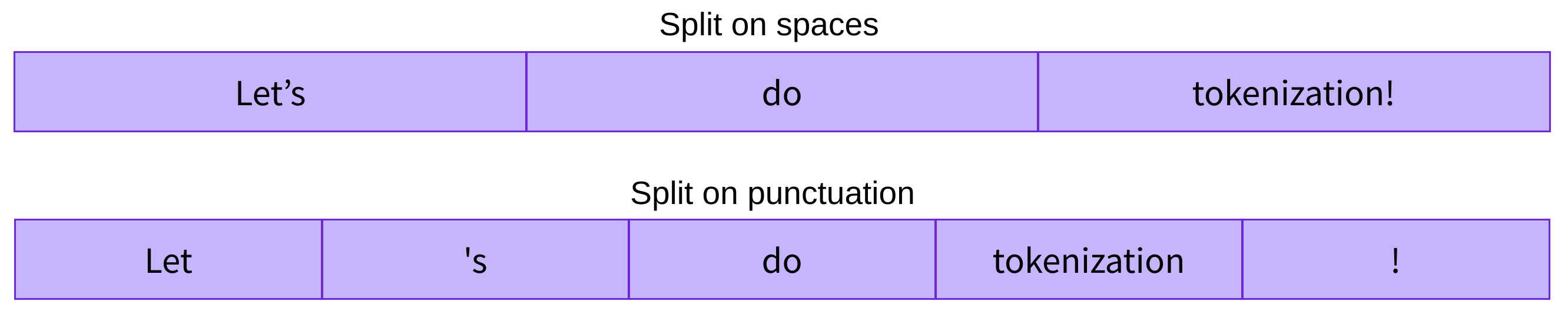
每个 word 都被赋予一个ID,这个 ID 的范围是从0到 vocabulary size,这种方式有一种问题,就是很容易出现例如,dog 和 dogs,虽然是相近的词,但是被分配了完全不同的无关的id。对于不在vocabulary 库里面的词,我们会分配 [UNK],代表未知词。
Character base
Char base的 tokenization 方式,就是用char,而不是word。 这种方式的好处在于:vocabulary size 很小;比较少机会出现 out of vocabulary 的问题。但这种方式会导致文本无意义
Subword tokenization
subword tokenization 依赖的原则是:常见词不应该分成subword,不常见的词应该分为更有意义的subword,例如:tokenization 代表不常见的词,可以被分为:token和ization,annoyingly 被分为 annoying 和 ly,这对于英文来说是很有意义的,因为英文本来就是由于词根和词缀组成的。
WordPiece
在BERT中采用的分词策略为WordPiece。WordPiece是贪心的最长匹配搜索算法。基本流程:
- 首先初始化词表,词表包含了训练数据中出现的所有字符。
- 然后两两拼接字符,统计字符对加入词表后对语言模型的似然值的提升程度。
- 选择提升语言模型似然值最大的一组字符对加入词表中。
反复2和3,直到词表大小达到指定大小。
Byte-level BPE
GPT-2中采用的分词策略为Byte-level BPE,即以字节为单位进行BPE。
load与save
载入方法采用from_pretrained;保存方法采用save_pretrained
Encoding
将文本转化为数字的过程为编码,主要包含两个步骤:tokenization和convert_tokens_to_ids。
-
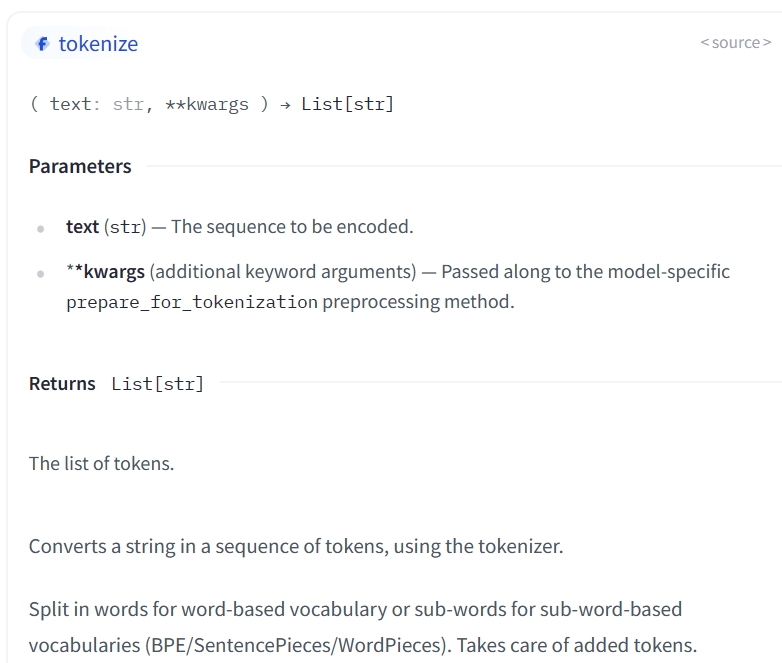
tokenization通过
tokenize方法实现
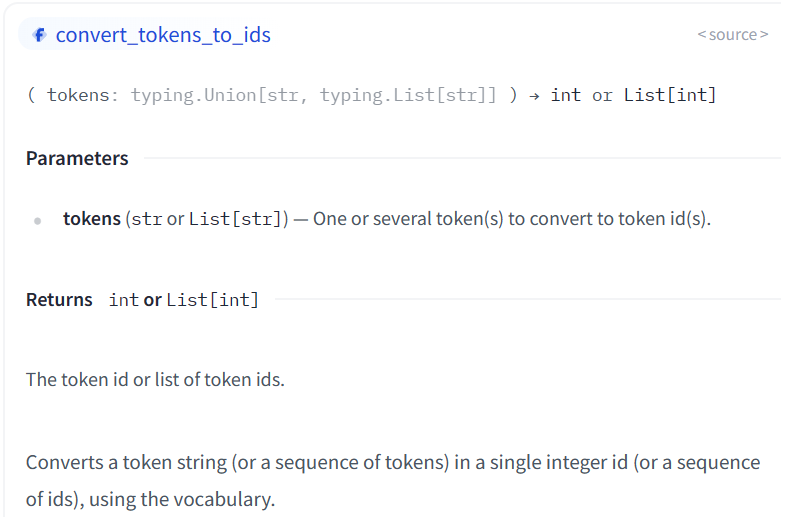
-
convert_tokens_to_ids
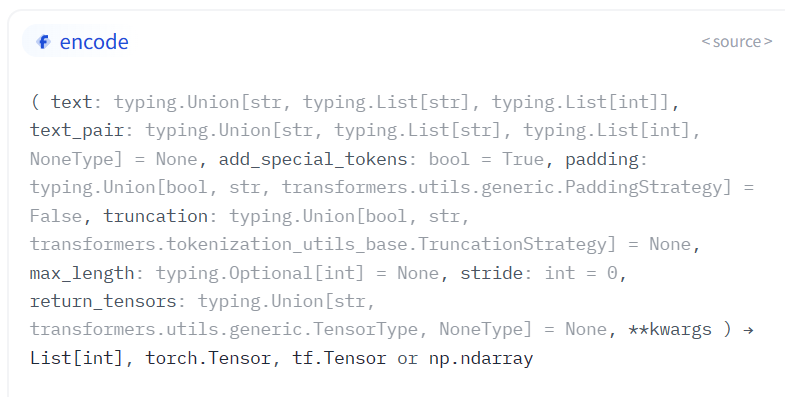
而encode接口可以实现两者结合
Decoding
将输出的 ids 转化为文本,这可以使用 tokenizer 的 decode 方法:

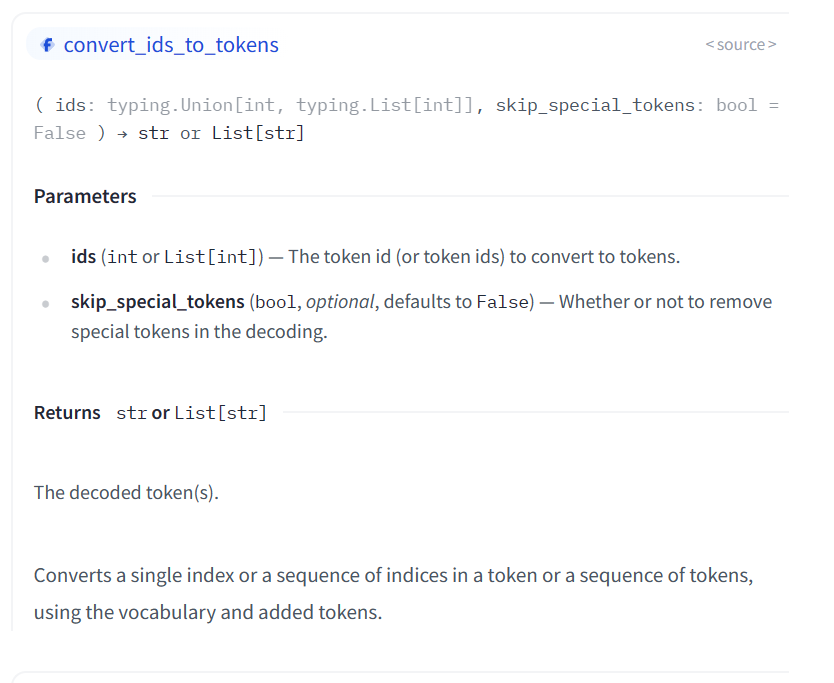
convert_ids_to_tokens
Attention masks
Attention masks 和输入的 input ids 具有完全一样的shape,其中1 代表了这个id需要attention,0代表这个id不需要attention。
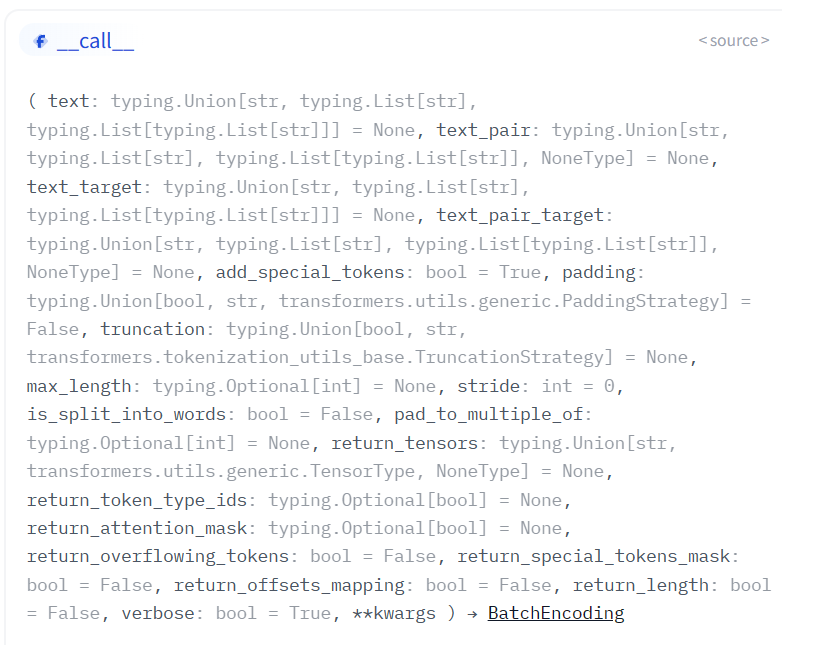
call
返回值

tokenize、encode、encode_plus和__call__
- tokenize返回词列表,默认首尾不加 [CLS] [SEP];
- encode返回词id列表,默认首尾加 [CLS] [SEP]对应的词id;
- encode_plus相较于encode,会多返回token_type_ids和attention_mask。