
各种卷积层
卷积可以捕获图像相邻像素的依赖性,起到类似滤波器的作用,得到不同形态的特征图。
普通卷积
1D卷积
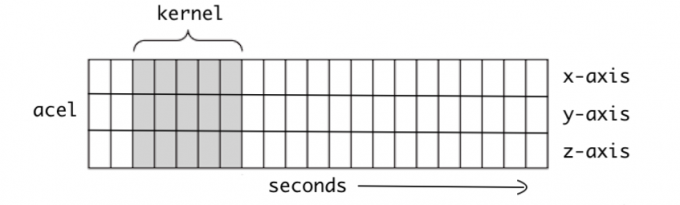
1D卷积主要应用于时序数据,上图所示的数据有三个数据点,卷积核沿着时间维度滑动。适用于音频和文本数据。
1 | class torch.nn.Conv1d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True) |
- in_channels(int) – 输入信号的通道。
- out_channels(int) – 卷积产生的通道。有多少个out_channels,就需要多少个1维卷积
- kernel_size(int or tuple) - 卷积核的尺寸,卷积核的大小为(k,),第二个维度是由in_channels来决定的,所以实际上卷积大小为kernel_size*in_channels
- stride(int or tuple, optional) - 卷积步长
- padding (int or tuple, optional)- 输入的每一条边补充0的层数
- dilation(int or tuple, `optional``) – 卷积核元素之间的间距
- groups(int, optional) – 从输入通道到输出通道的阻塞连接数
- bias(bool, optional) - 如果bias=True,添加偏置
2D卷积
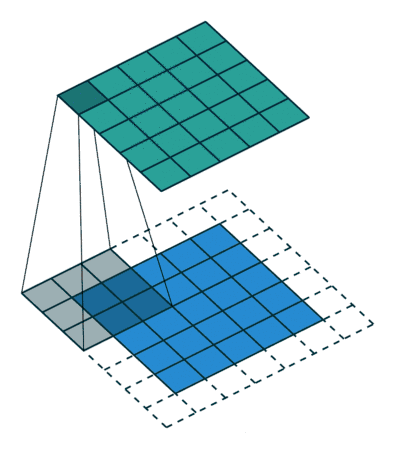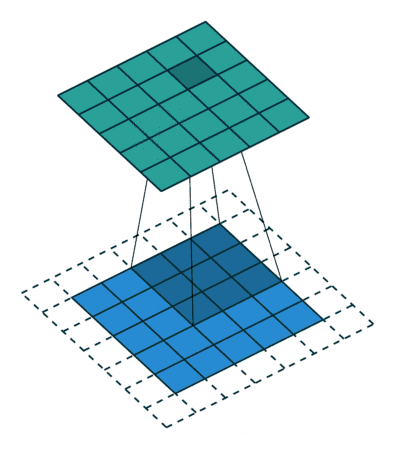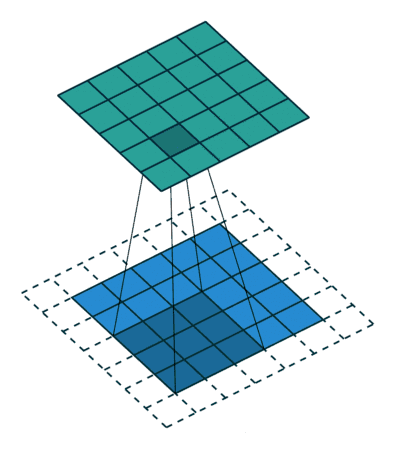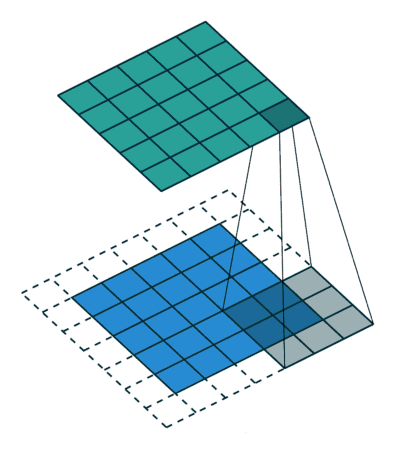
2D卷积是常用的卷积形式。执行卷积的目的是从输入中提取有用的特征。在图像处理中,执行卷积操作有诸多不同的过滤函数可供选择,每一种都有助于从输入图像中提取不同的方面或特征,如水平/垂直/对角边等。类似地,卷积神经网络通过卷积在训练期间使用自动学习权重的函数来提取特征。所有这些提取出来的特征,之后会被「组合」在一起做出决策。优点:权重共享(weights sharing)和平移不变性(translation invariant),可以考虑像素空间的关系。
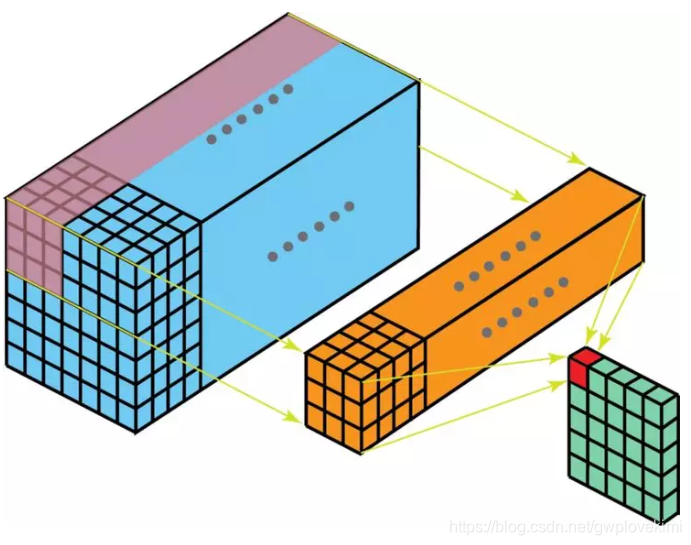
多通道卷积
1 | torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True) |
| 参数 | 参数类型 | 描述 |
|---|---|---|
| in_channels | int | 输入图像通道数 |
| out_channels | int | 卷积产生的通道数 |
| kernel_size | int or tuple | 卷积核尺寸,可以设为1个int型数或者一个(int, int)型的元组。例如(2,3)是高2宽3卷积核 |
| stride | int or tuple (optional) | 卷积步长,默认为1。可以设为1个int型数或者一个(int, int)型的元组。 |
| padding | int or tuple (optional) | 填充操作 |
| padding_mode | string (optional) | padding模式,‘zeros’, ‘reflect’, ‘replicate’ or ‘circular’. Default: ‘zeros’。 |
| dilation | int or tuple (optional) | 扩张操作:控制kernel点(卷积核点)的间距,默认值:1。 |
| groups | int (optional) | group参数的作用是控制分组卷积,默认不分组,为1组。 |
| bias | bool (optional) | 为真,则在输出中添加一个可学习的偏差。默认:True。 |
3D卷积
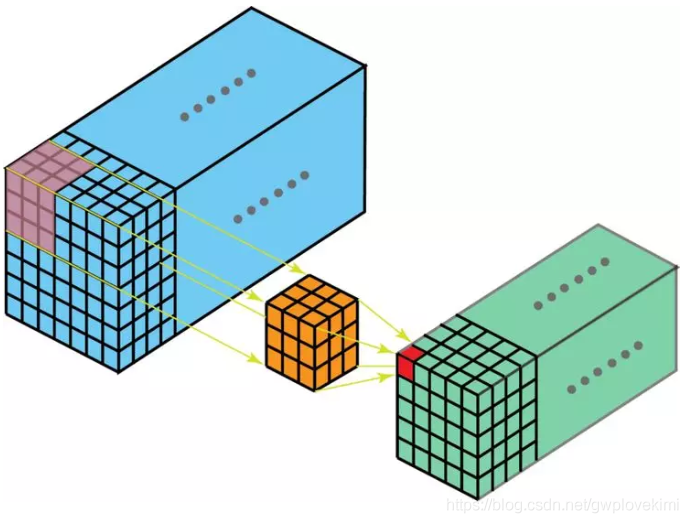
在 3D 卷积中,过滤器的深度要比输入层的深度更小(卷积核大小<通道大小),结果是,3D 过滤器可以沿着所有 3 个方向移动(高、宽以及图像的通道)。每个位置经过元素级别的乘法和算法都得出一个数值。由于过滤器滑动通过 3D 空间,输出的数值同样也以 3D 空间的形式呈现,最终输出一个 3D 数据。
1 | class torch.nn.Conv3d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True) |
| 参数 | 参数类型 | 描述 |
|---|---|---|
| kernel_size | int or tuple | 假设为(a,b,c),表示的是过滤器每次处理 a 帧图像,该图像的大小是b x c。 |
| stride | int or tuple | 卷积步长,形状是三维的,假设为(x,y,z),表示的是三维上的步长是x,在行方向上步长是y,在列方向上步长是z。 |
| padding | int or tuple | 输入的每一条边补充0的层数,形状是三维的,假设是(l,m,n),表示的是在输入的三维方向前后分别padding l 个全零二维矩阵,在输入的行方向上下分别padding m 个全零行向量,在输入的列方向左右分别padding n 个全零列向量。 |
1x1卷积
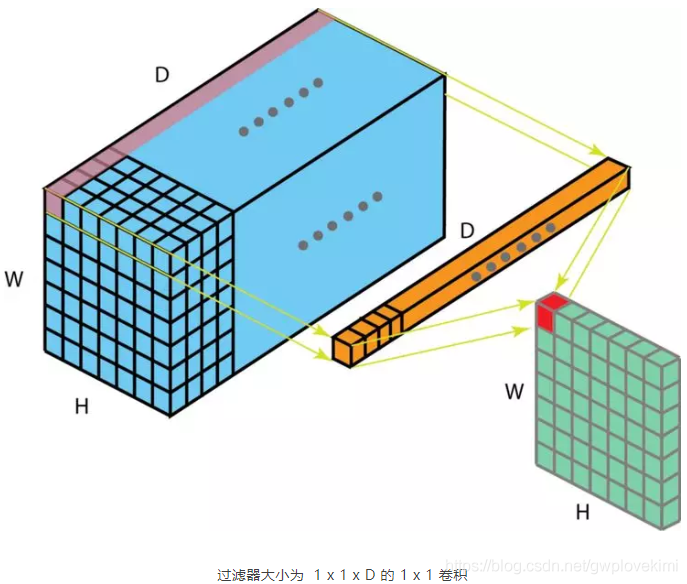
在执行计算昂贵的 3 x 3 卷积和 5 x 5 卷积前,往往会使用 1 x 1 卷积来减少计算量。此外,它们也可以利用调整后的线性激活函数来实现双重用途。
优点:
- 不改变图像的结构:保留图像局部特征,卷积具有空间不变性;
- 输入可以是任意尺寸;
- 通过控制卷积核个数实现升维或者降维,从而减少模型参数;
- 用于不同channel上特征的融合;
- 对不同特征进行归一化操作;
- 引入非线性;
分组卷积
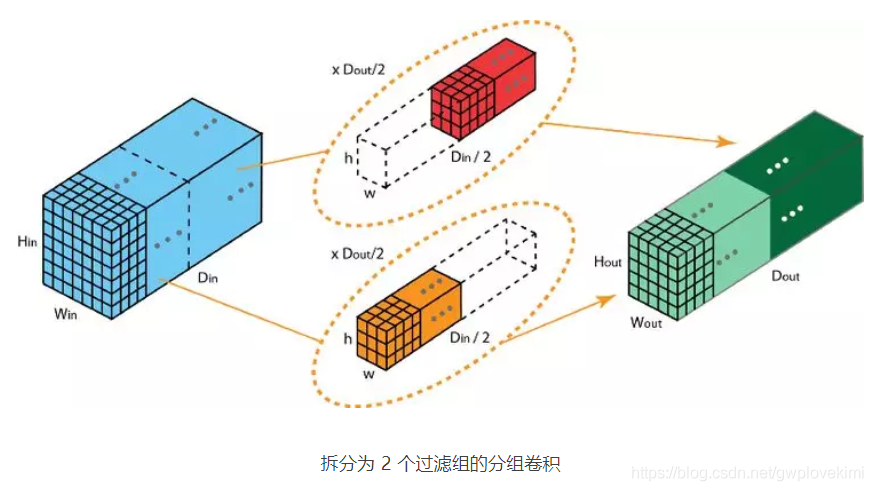
深度可分离卷积
深度可分离卷积主要分为两个过程,分别为逐通道卷积(Depthwise Convolution)和逐点卷积(Pointwise Convolution)。
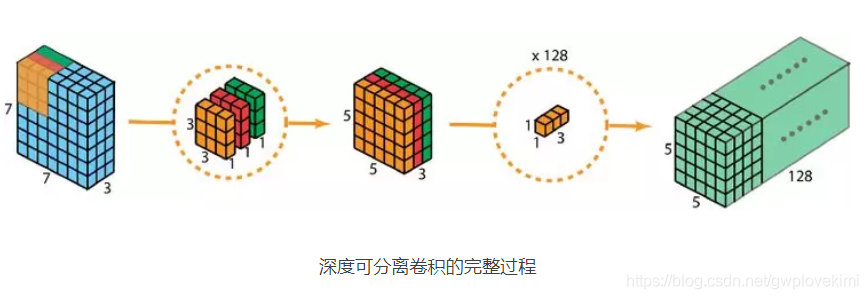
优点:降低参数量
1 | conv1 = nn.Conv2d(in_channels, in_channels, kernel_size=3, stride=2, padding=1, groups=in_channels, bias=False) |
空间可分离卷积
空间可分离卷积:将一个卷积核分为两部分(降低计算复杂度,但并非所有的卷积核都可以分)

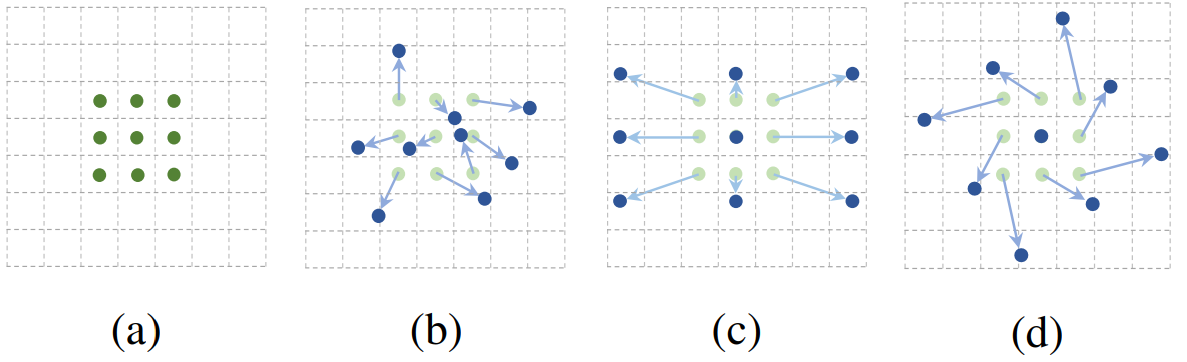
可形变卷积
空洞卷积
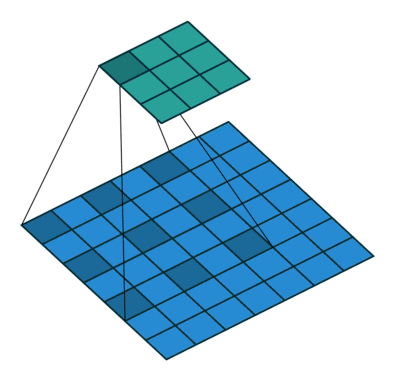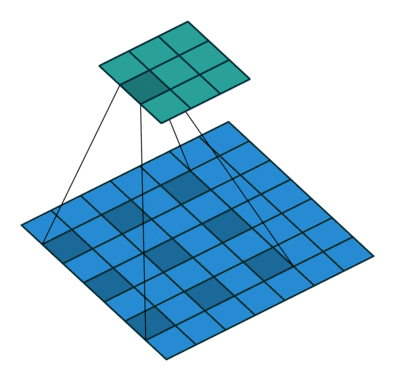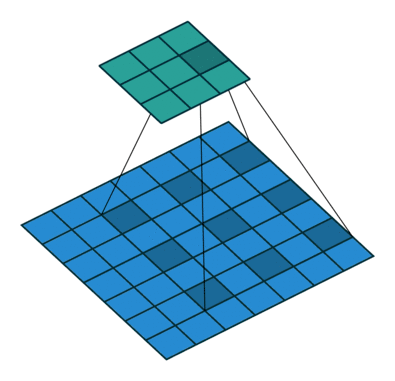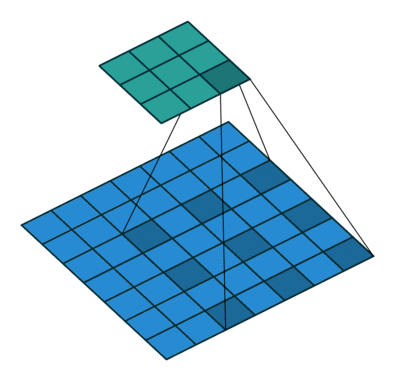
1 | conv2 = nn.Conv2d(1, 1, 3, stride=1, bias=False, dilation=2) |
优点:
- 增大了卷积输出每个点的感受野,并且不向pooling会丢失信息,在图像需要全局信息或这从较长的sequence依赖的序列问题上有着较广泛的应用。
- 捕获多尺度上下文信息:设置不同的dilation参数,感受野不同,即获得了不同尺度特征。
存在的问题:
- 在空洞卷积叠加的情况下,图像中不同像素点参与运算的分布不均匀
- 局部信息丢失:某一层得到的卷积结果来自上一层的独立集合,没有相互依赖,会导致结果之间没有相关性。
- 远距离获取的信息没有相关性:远距离的信息可能会引入噪声;
转置卷积
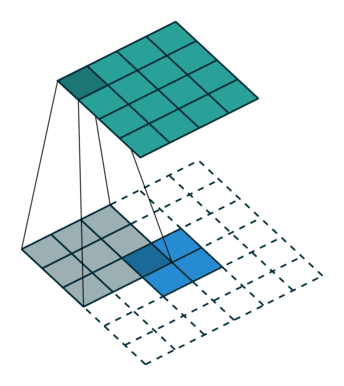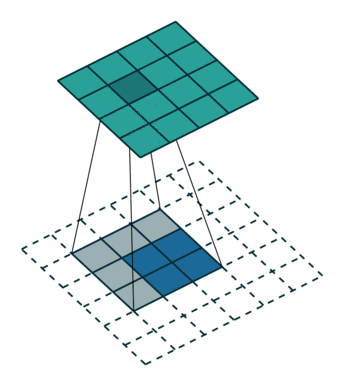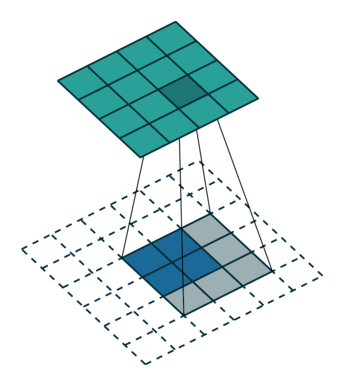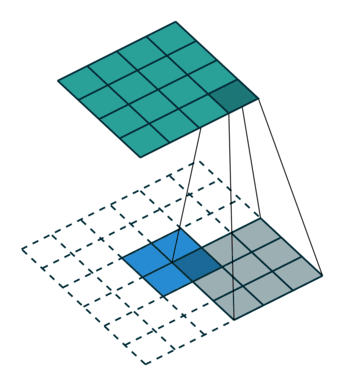
转置卷积,是因为用矩阵乘法实现卷积操作时,需要对左乘的矩阵转置,与卷积操作刚好相反,但转置卷积不是卷积的逆运算。
一般的卷积运算可以看成是一个其中非零元素为权重的稀疏矩阵W与输入的图像进行矩阵相乘,反向传播时的运算实质为W的转置与loss对输出y的导数矩阵的矩阵相乘。
逆卷积的运算过程与卷积正好相反,是正向传播时做成W的转置,反向传播时左乘W。
转置卷积可以实现上采样和近似重构输入图像,卷积层可视化。
参考
各种卷积层的理解(深度可分离卷积、分组卷积、扩张卷积、反卷积)
深度可分离卷积
可变形卷积从概念到实现过程
Deformable Convolutional Networks

