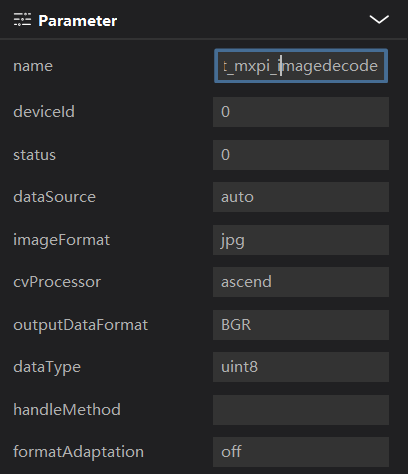
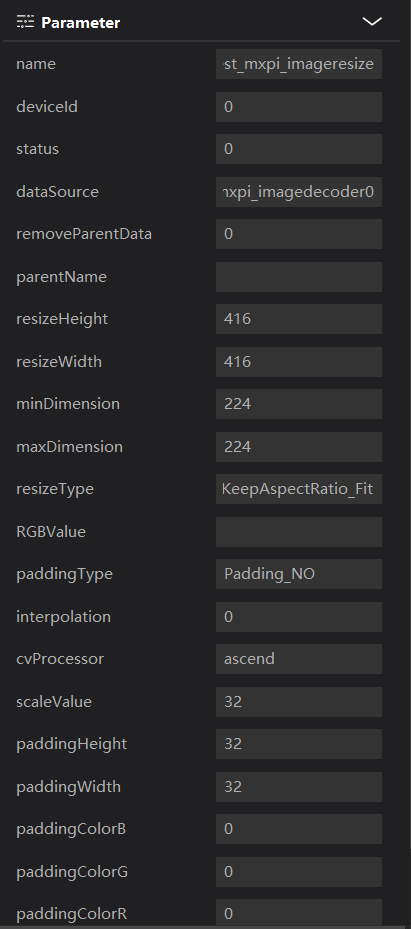
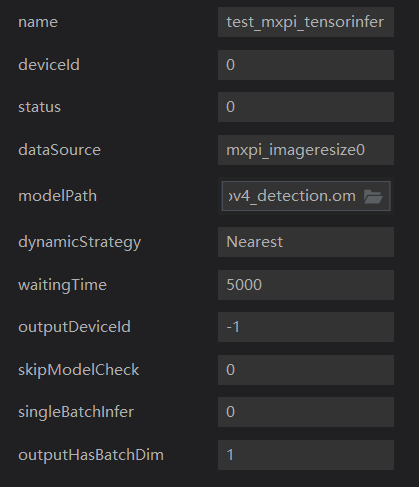
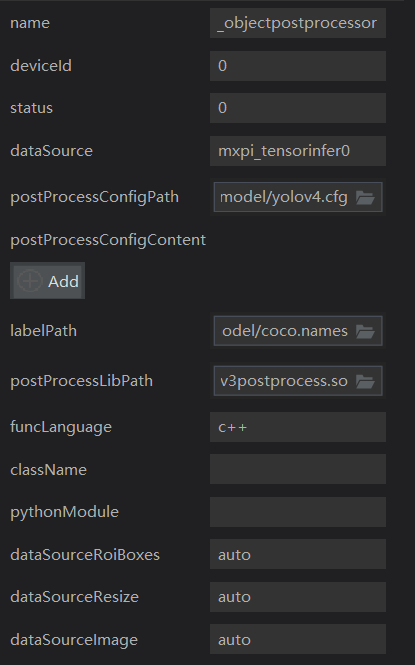
streamManagerApi = StreamManagerApi() # init stream manager ret = streamManagerApi.InitManager() if ret != 0: print("Failed to init Stream manager, ret=%s" % str(ret)) exit()
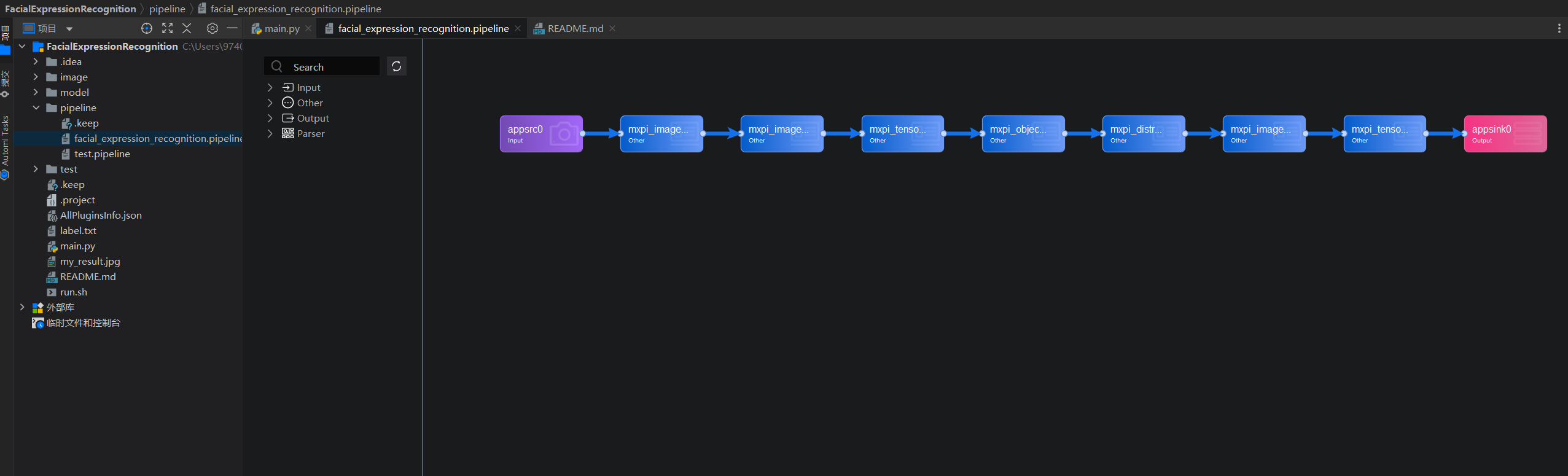
# create streams by pipeline config file pipeline_path = b"./pipeline/facial_expression_recognition.pipeline" ret = streamManagerApi.CreateMultipleStreamsFromFile(pipeline_path) if ret != 0: print("Failed to create Stream, ret=%s" % str(ret)) exit()
喂入数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14
img_path = "image/test_1.jpg" streamName = b"detection" inPluginId = 0 dataInput = MxDataInput() try: withopen(img_path, 'rb') as f: dataInput.data = f.read() except: print("No such image") exit() ret = streamManagerApi.SendData(streamName, inPluginId, dataInput) if ret < 0: print("Failed to send data to stream") exit()
if infer_result.size() == 0: print("infer_result is null") exit() if infer_result.size() < 4: print("No area of the face was detected in the picture") exit()
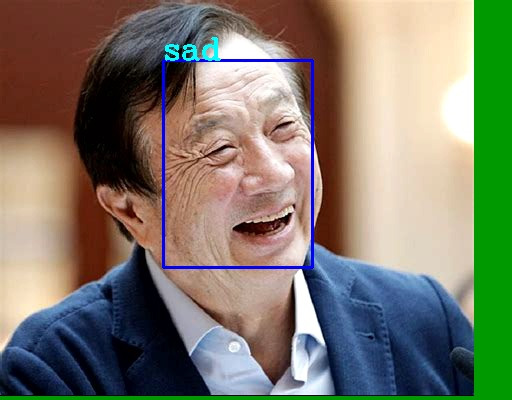
# print the infer result for i, _ inenumerate(tensorList3.tensorPackageVec): res1 = np.frombuffer(tensorList3.tensorPackageVec[i].tensorVec[0].dataStr, dtype = np.float32) maxindex = np.argmax(res1)