
【MindStudio训练营第一季】综合应用
本次利用MindStudio实现图片上色,并对模型进行分析。参考代码为colorization
模型介绍
背景
论文发表在2016年ECCV,在当时图像着色方面取得了进步,主要体现在损失函数的设计维持了色彩的多样性;同时引入了一种新的着色算法评估框架;采用自监督学习在基准上取得了较好的效果。
值得注意的是,本文并不是恢复灰度图的真实颜色,而是利用灰度图中物体的纹理、语义等信息作为线索来预测图片可能的颜色,上色的结果只要合理即可,这样降低了上色的难度,同时也符合预期。
动机
本文主要解决2015年时图像着色饱和度较低的问题。因此,本文为每个像素预测一个颜色分布,鼓励探索颜色的多样性。
模型
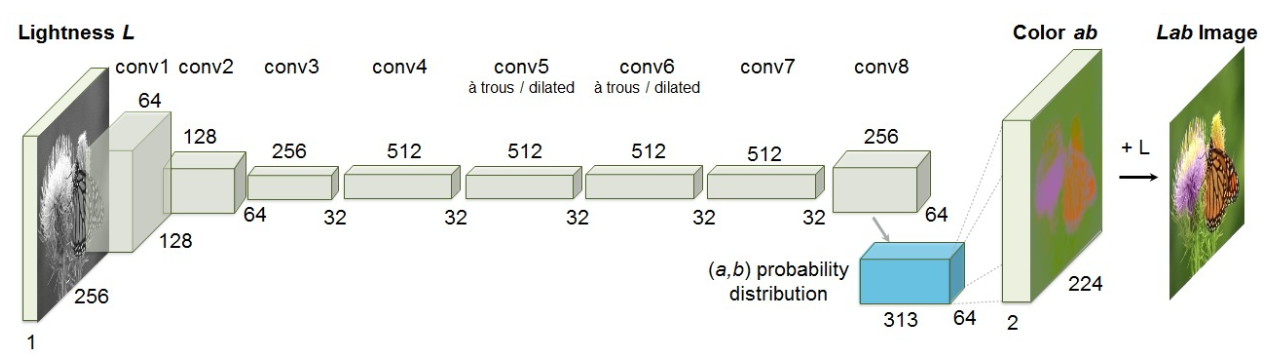
本文模型较为简单,采用Lab色彩空间,输入图片的L通道,使用卷积神经网络预测对应的ab通道取值的概率分布,最后转为RGB图像。
1 | Lab颜色模型由三个要素组成,一个要素是亮度(L),a和b是两个颜色通道。 |
推理运行
环境配置
本次程序中采用到了第三方依赖:opencv,ffmpeg和acllite,因此在运行前需要配置环境。
安装准备
首先需要添加环境变量,确保第三方依赖编译成功。
1 | # 打开文件 |
创建第三方依赖文件夹并下载依赖公共文件
1 | # 创建第samples相关依赖文件夹 |
安装opencv
直接使用apt-get安装
1 | sudo apt-get install libopencv-dev |
安装ffmpeg和x246插件
源码安装x246
1 | # 下载 |
源码安装ffmpeg
1 | # 下载 |
安装acllite库
1 | # 编译并安装acllite |
模型转换
准备代码、测试图片以及Caffe模型,得到如下文件
1 | . |
MindStudio中配置Deployment,工具->Deployment->Configuration,之后上次文件到ECS。
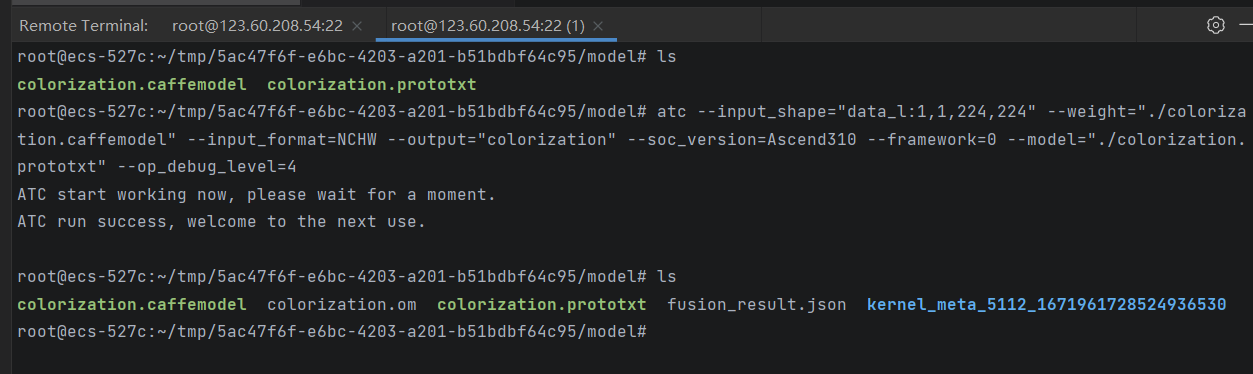
利用ATC进行模型转换,命令如下:
1 | atc --input_shape="data_l:1,1,224,224" --weight="./colorization.caffemodel" --input_format=NCHW --output="colorization" --soc_version=Ascend310 --framework=0 --model="./colorization.prototxt" --op_debug_level=4 |
参数说明
| 参数名称 | 参数值 | 参数说明 |
|---|---|---|
| input_shape | 1,1,224,224 | 输入数据的shape |
| model | colorization.prototxt | 模型文件路径 |
| weight | colorization.caffemodel | 权重文件路径 |
| output | colorization | 输出模型路径 |
| framework | 0 | 原始框架类型,0值Caffe |
| input_format | NCHW | 输入数据格式,Caffe默认为NCHW |
| op_debug_level | 4 | TBE算子编译debug功能开关 |
| soc_version | Ascend310 | 芯片版本 |
关于framework参数值
- 0:Caffe
- 1:MindSpore
- 3:TensorFlow
- 5:ONNX
关于op_debug_level参数值:
- 0:不开启算子debug功能,在执行atc命令当前路径不生成算子编译目录kernel_meta。
- 1:开启算子debug功能,在执行atc命令当前路径算子编译生成的kernel_meta文件夹中生成TBE指令映射文件(算子cce文件*.cce和python-cce映射文件*_loc.json),用于后续工具进行AICore Error问题定位。
- 2:开启算子debug功能,在执行atc命令当前路径算子编译生成的kernel_meta文件夹中生成TBE指令映射文件(算子cce文件*.cce和python-cce映射文件*_loc.json),并关闭编译优化开关并且开启ccec调试功能(ccec编译器选项设置为-O0-g),用于后续工具进行AICore Error问题定位。
- 3:不开启算子debug功能,在执行atc命令当前路径算子编译生成的kernel_meta文件夹中保留.o(算子二进制文件)和.json文件(算子描述文件)。
- 4:不开启算子debug功能,在执行atc命令当前路径算子编译生成的kernel_meta文件夹中保留.o(算子二进制文件)和.json文件(算子描述文件),并生成TBE指令映射文件(算子cce文件*.cce)和UB融合计算描述文件({$kernel_name}_compute.json)。
更多参数见参数概览
通过MindStudio建立SSH连接,工具 -> start SSH session:
使用msame工具进行性能测试
-
安装msame
下载Ascend / tools,找到msame,运行编译脚本,此时出现
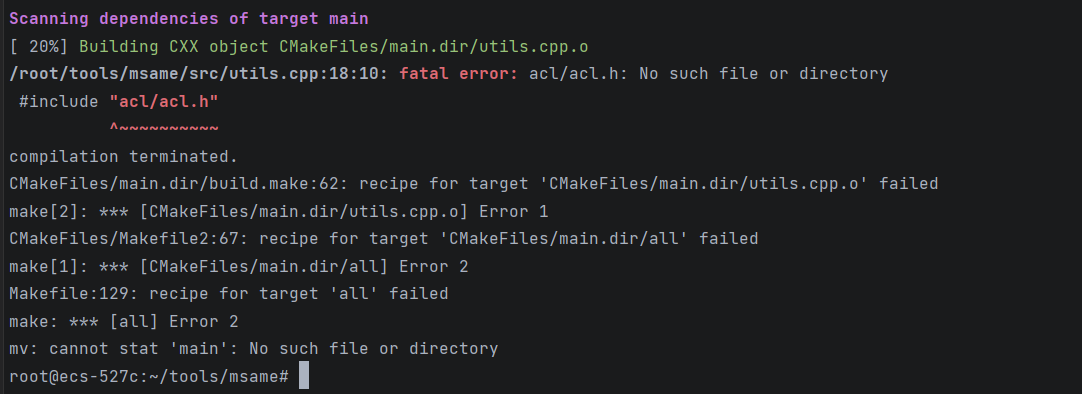
解决方法:在src/CMakeLists.txt中的include_directories中修改实际的Ascend安装位置
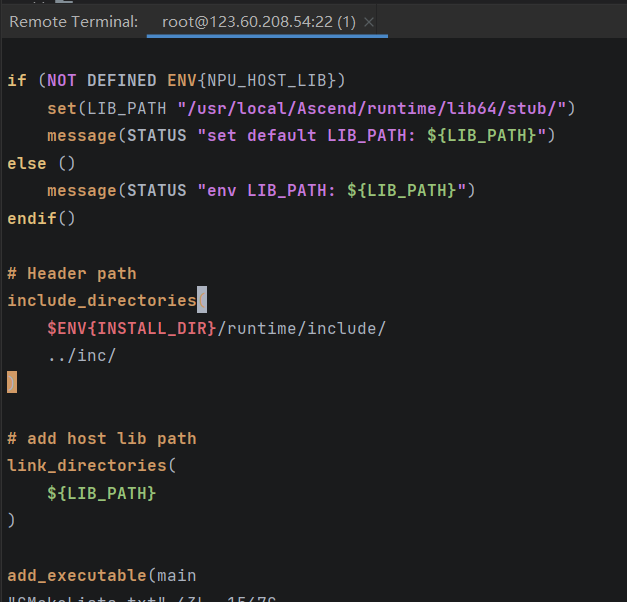
再执行编译脚本./build.sh g++ $HOME/tools/msame/out -
性能测试
执行msame --model colorization.om --output output/ --loop 100
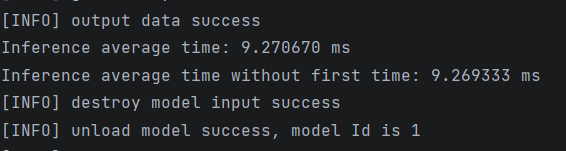
平均推理性能为9.269ms
配置编译和运行
-
构建 -> Configuration

-
运行 -> 编辑配置
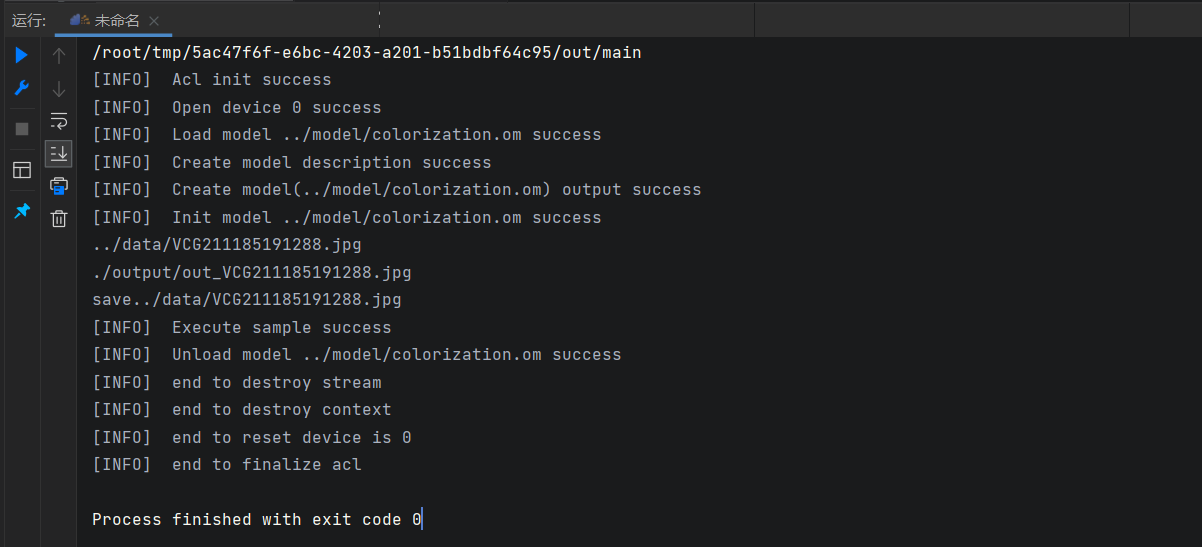
实验结果
利用Deployment从ECS同步文件
| 源图 | 着色图 |
|---|---|
 |
 |
精度比对
比对数据准备
生成dump数据文件
-
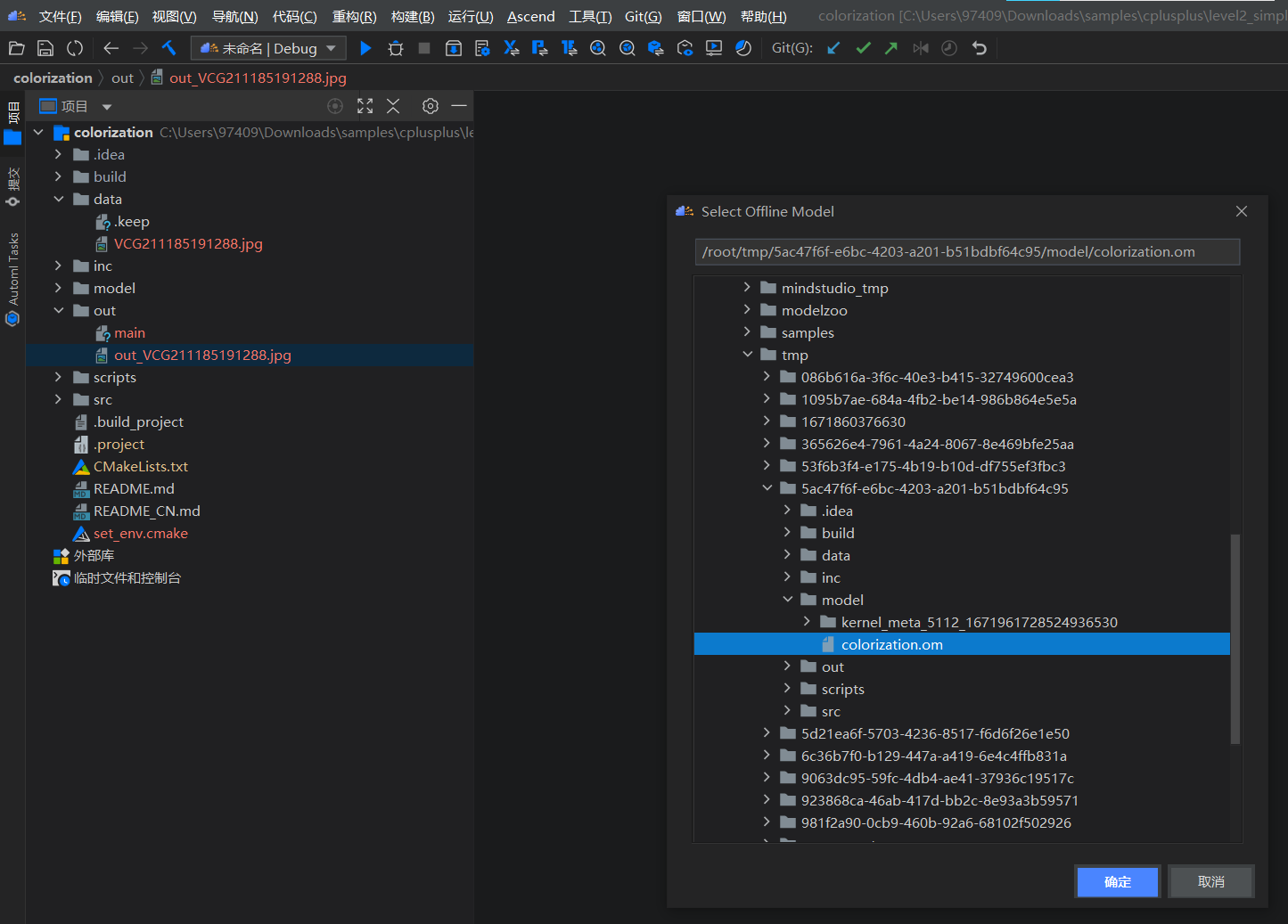
选择
Ascend > Dump Configuration菜单,弹出Select Offline Model窗口,选择.om模型
-
设置
.om模型文件的dump配置项,所有算子开启dump,同时dump算子的输入、输出数据,设置保存dump文件的路径和acl配置文件。更多参数说明,可以参考 参数说明
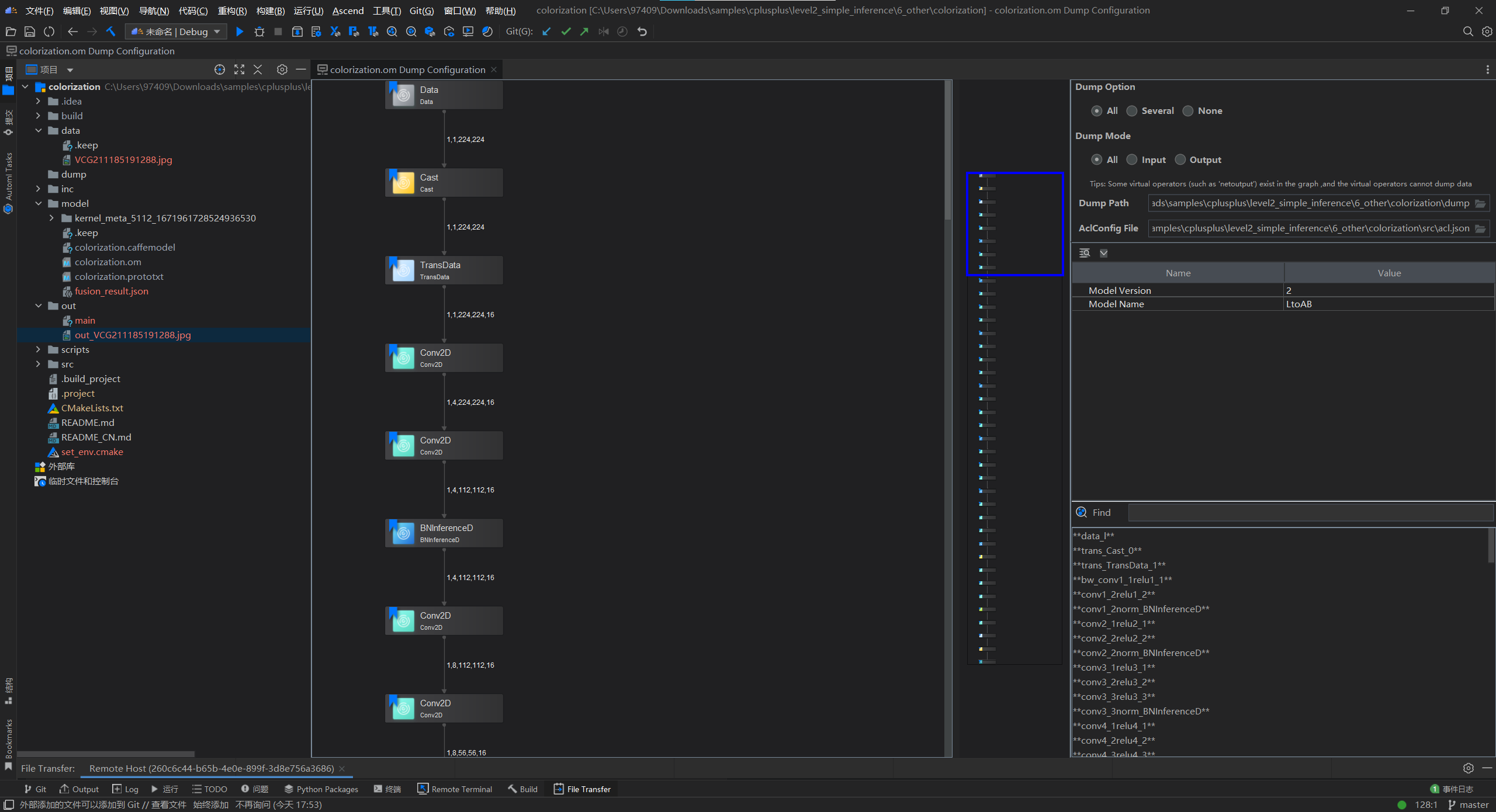
仔细观察上图可以发现Dump Path为本地路径,并且无法设置为远程路径,这是可以手动修改acl.json文件,配置正确的路径与名称。
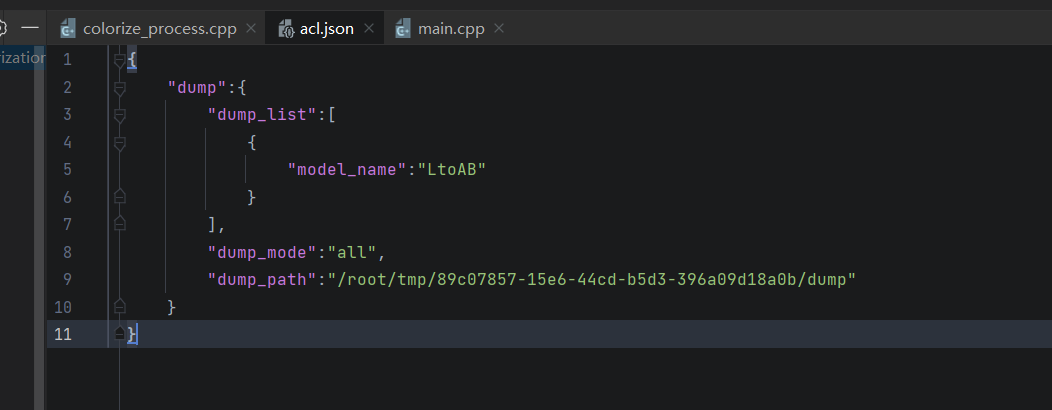
-
设置dump完成后,重新编译和运行应用工程。

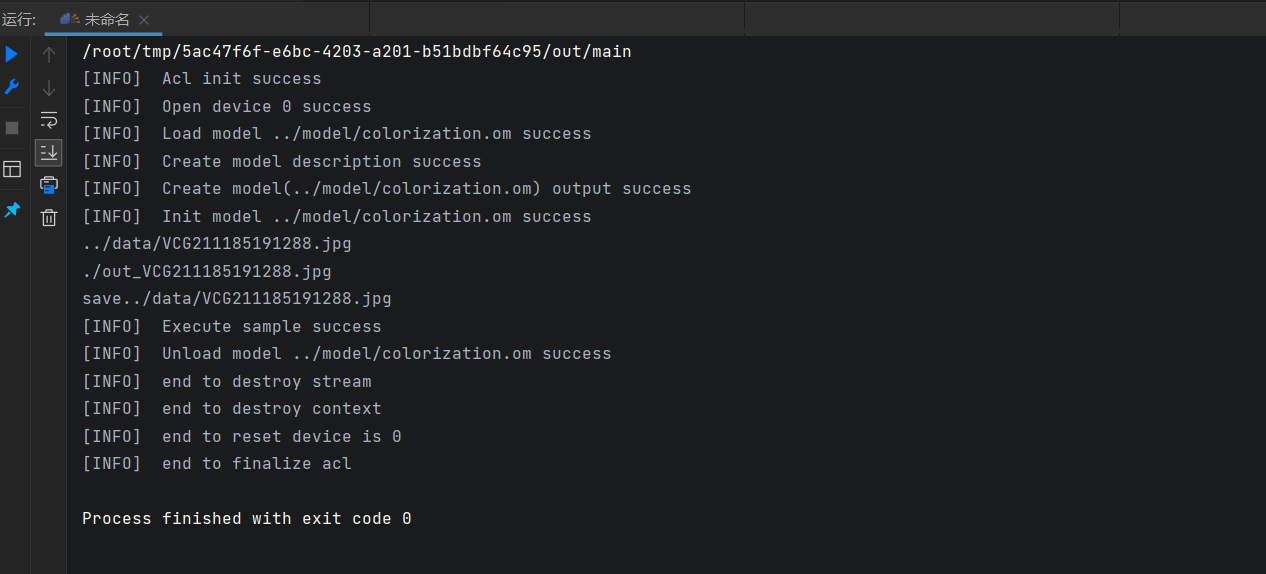
由此得到NPU侧的dump数据
准备Caffe模型npy数据文件
-
安装Caffe
这里直接使用apt install caffe-cpu,但需要注意的是python版本不能太高,一开始在提供的镜像3.9下安装成功但是import失败,后来使用Ubuntu18.04公共镜像Python3.6版本安装成功。 -
获取输入图片
获取caffe推理数据时需要输入.bin图片文件,同时为了保证输入到caffe和om模型的图片相同这里需要了解图片预处理的过程,具体代码位于src/colorize_process.cpp的preprocess方法中,代码如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15// read image using OPENCV
cv::Mat mat = cv::imread(imageFile, CV_LOAD_IMAGE_COLOR);
//resize
cv::Mat reiszeMat;
cv::resize(mat, reiszeMat, cv::Size(modelWidth_, modelHeight_));
// deal image
reiszeMat.convertTo(reiszeMat, CV_32FC3);
reiszeMat = 1.0 * reiszeMat / 255;
cv::cvtColor(reiszeMat, reiszeMat, CV_BGR2Lab);
// pull out L channel and subtract 50 for mean-centering
std::vector<cv::Mat> channels;
cv::split(reiszeMat, channels);
cv::Mat reiszeMatL = channels[0] - 50;阅读代码可知,采用OPENCV读入图片,缩放至
224*224大小,然后将像素值缩放[0-1]区间,BGR转为Lab色域,提取L通道数据并进行中心化,最终得到reiszeMatL,既为模型输入。对此通过保存为.bin文件1
2
3
4
5
6
7
8
9
10std::ofstream fout1("./test.bin", std::ios::binary | std::ios::trunc);
cv::Mat flowU = cv::Mat::zeros(224, 224, CV_32FC1);
for (int i = 0; i < 224; i++)
{
for (int j = 0; j < 224; j++)
{
fout1.write(reinterpret_cast<char*>(&flowU.at<float>(i, j)), sizeof(float));
}
}
fout1.close(); -
去除原始Caffe模型文件中的in-place
为确保生成符合命名要求的.npy文件,需要对原始的Caffe模型文件去除in-place,生成新的.prototxt模型文件用于生成.npy文件(例如:如果有未去除in-place的A、B、C、D四个融合算子,进行dump数据,输出的结果为D算子的结果,但命名却是A算子开头,就会导致比对时找不到文件)。
进入ascend-toolkit安装目录,找到latest/tools/operator_cmp/compare下的inplace_layer_process.py脚本,运行1
python3 inplace_layer_process.py -i colorization.prototxt
得到new_colorization.prototxt
-
推理获得caffe运行结果
caffe_dump.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120# coding=utf-8
import caffe
import sys
import argparse
import os
import caffe.proto.caffe_pb2 as caffe_pb2
import google.protobuf.text_format
import json
import numpy as np
import time
TIME_LENGTH = 1000
FILE_PERMISSION_FLAG = 0o600
class CaffeProcess:
def __init__(self):
parse = argparse.ArgumentParser()
parse.add_argument("-w", dest="weight_file_path",
help="<Required> the caffe weight file path",
required=True)
parse.add_argument("-m", dest="model_file_path",
help="<Required> the caffe model file path",
required=True)
parse.add_argument("-o", dest="output_path", help="<Required> the output path",
required=True)
parse.add_argument("-i", "--input_bins", dest="input_bins", help="input_bins bins. e.g. './a.bin;./c.bin'",
required=True)
parse.add_argument("-n", "--input_names", dest="input_names",
help="input nodes name. e.g. 'graph_input_0:0;graph_input_0:1'",
required=True)
args, _ = parse.parse_known_args(sys.argv[1:])
self.weight_file_path = os.path.realpath(args.weight_file_path)
self.model_file_path = os.path.realpath(args.model_file_path)
self.input_bins = args.input_bins.split(";")
self.input_names = args.input_names.split(";")
self.output_path = os.path.realpath(args.output_path)
self.net_param = None
self.cur_layer_idx = -1
def _check_file_valid(path, is_file):
if not os.path.exists(path):
print('Error: The path "' + path + '" does not exist.')
exit(-1)
if is_file:
if not os.path.isfile(path):
print('Error: The path "' + path + '" is not a file.')
exit(-1)
else:
if not os.path.isdir(path):
print('Error: The path "' + path + '" is not a directory.')
exit(-1)
def _check_arguments_valid(self):
self._check_file_valid(self.model_file_path, True)
self._check_file_valid(self.weight_file_path, True)
self._check_file_valid(self.output_path, False)
for input_file in self.input_bins:
self._check_file_valid(input_file, True)
def calDataSize(shape):
dataSize = 1
for dim in shape:
dataSize *= dim
return dataSize
def _load_inputs(self, net):
inputs_map = {}
for layer_name, blob in net.blobs.items():
if layer_name in self.input_names:
input_bin = np.fromfile(
self.input_bins[self.input_names.index(layer_name)], np.float32)
input_bin_shape = blob.data.shape
if self.calDataSize(input_bin_shape) == self.calDataSize(input_bin.shape):
input_bin = input_bin.reshape(input_bin_shape)
else:
print("Error: input node data size %d not match with input bin data size %d.", self.calDataSize(
input_bin_shape), self.calDataSize(input_bin.shape))
exit(-1)
inputs_map[layer_name] = input_bin
return inputs_map
def process(self):
"""
Function Description:
process the caffe net, save result as dump data
"""
# check path valid
self._check_arguments_valid()
# load model and weight file
net = caffe.Net(self.model_file_path, self.weight_file_path,
caffe.TEST)
inputs_map = self._load_inputs(net)
for key, value in inputs_map.items():
net.blobs[key].data[...] = value
# process
net.forward()
# read prototxt file
net_param = caffe_pb2.NetParameter()
with open(self.model_file_path, 'rb') as model_file:
google.protobuf.text_format.Parse(model_file.read(), net_param)
for layer in net_param.layer:
name = layer.name.replace("/", "_").replace(".", "_")
index = 0
for top in layer.top:
data = net.blobs[top].data[...]
file_name = name + "." + str(index) + "." + str(
round(time.time() * 1000000)) + ".npy"
output_dump_path = os.path.join(self.output_path, file_name)
np.save(output_dump_path, data)
os.chmod(output_dump_path, FILE_PERMISSION_FLAG)
print('The dump data of "' + layer.name
+ '" has been saved to "' + output_dump_path + '".')
index += 1
if __name__ == "__main__":
caffe_process = CaffeProcess()
caffe_process.process()运行
1
python3 caffe_dump.py -m new_colorization.prototxt -w colorization.caffemodel -i test.bin -n 'data:0' -o ./output_dir
得到下列文件

比对
-
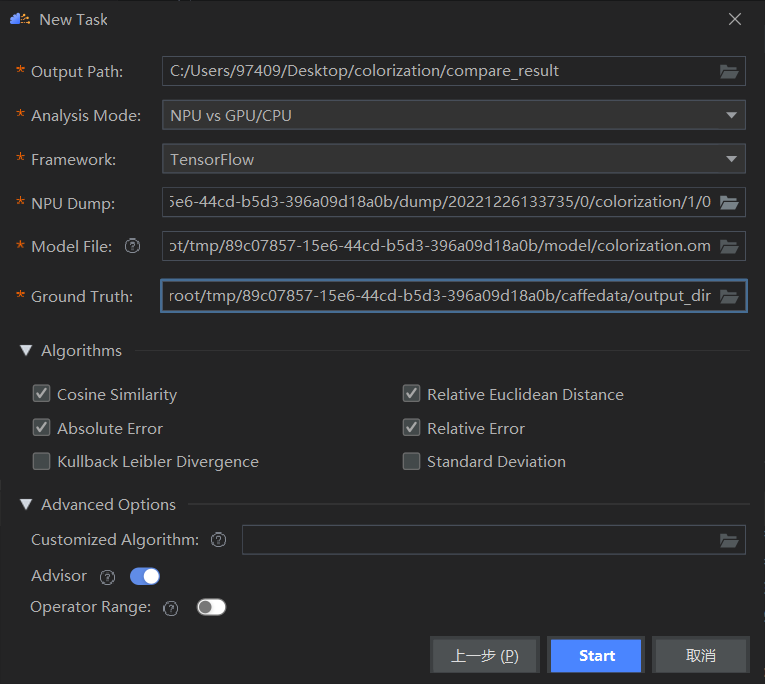
新建比对任务
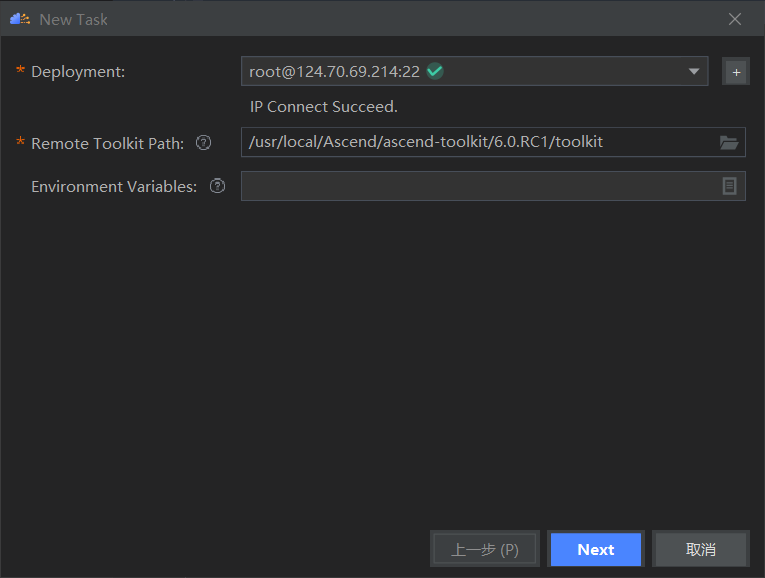
填入比对任务参数,具体参数说明可以查看比对操作
-
整网比对结果
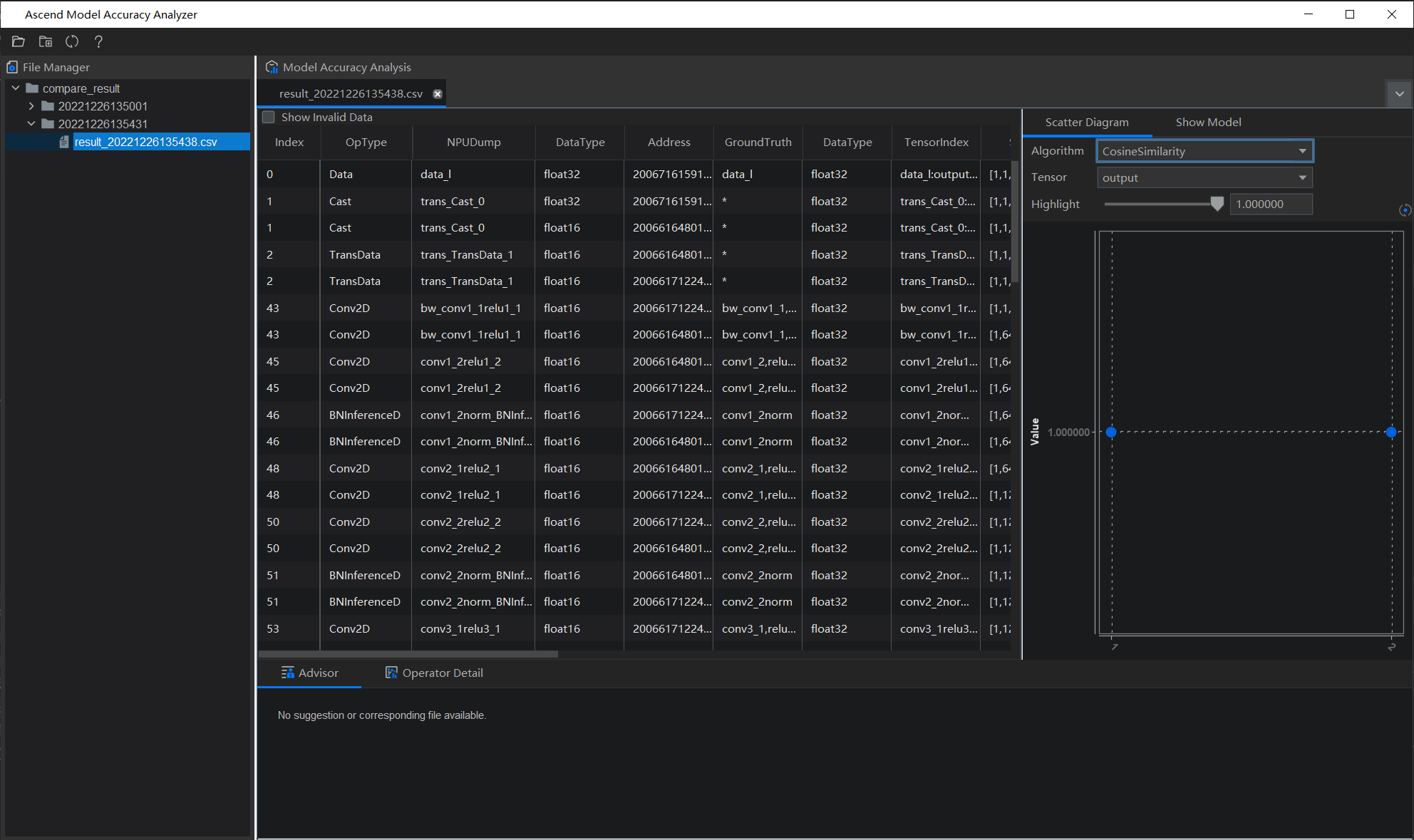
由上述界面可以查看精度比对,各项算法指标的散点分布图和模型可视化,可见整体而言两者精度较高。下方会提供专家系统提供的精度比对结果的结果分析,本次没有给出建议。
目前支持的分析检测类型有:FP16溢出检测、输入不一致检测、整网一致性检测(整网一致性检测包括:问题节点检测、单点误差检测和一致性检测)点击advisor旁边的Operator Detail可以查看单算子比对结果。
Profiling
采集和分析运行在昇腾AI处理器上的推理业务(应用或算子)各个运行阶段的关键性能指标。
采集数据
Ascend -> System Profiler -> New Project
新建项目
配置路径和环境,具体可参考 Profiling数据采集
配置采集项
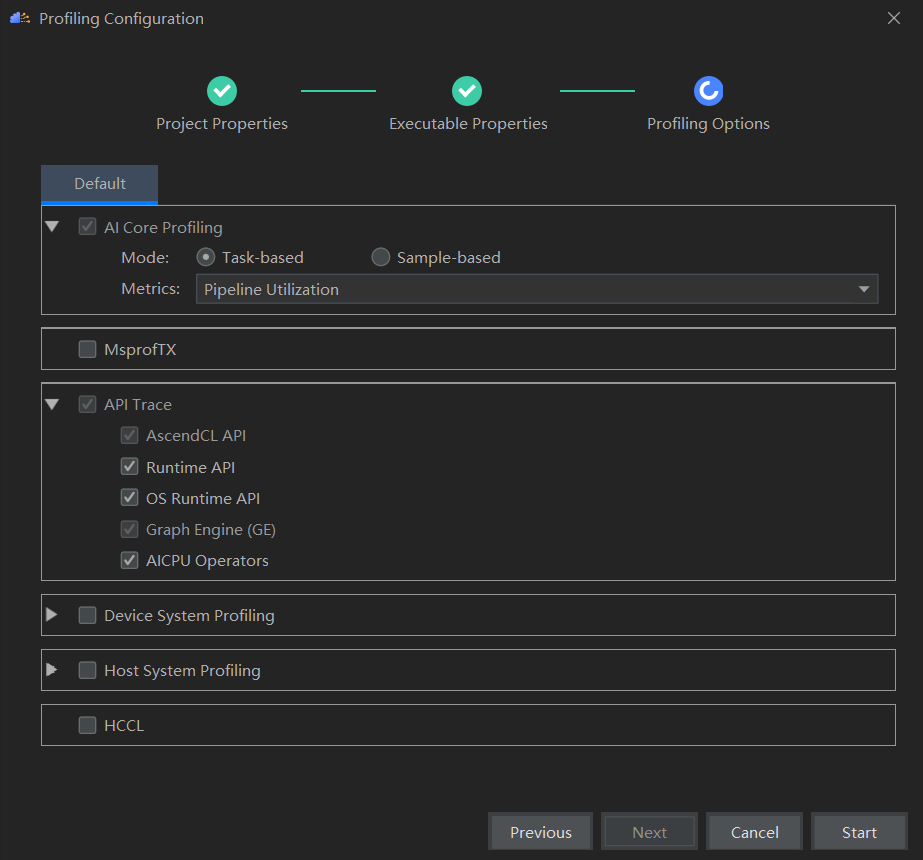
启动,出现错误,
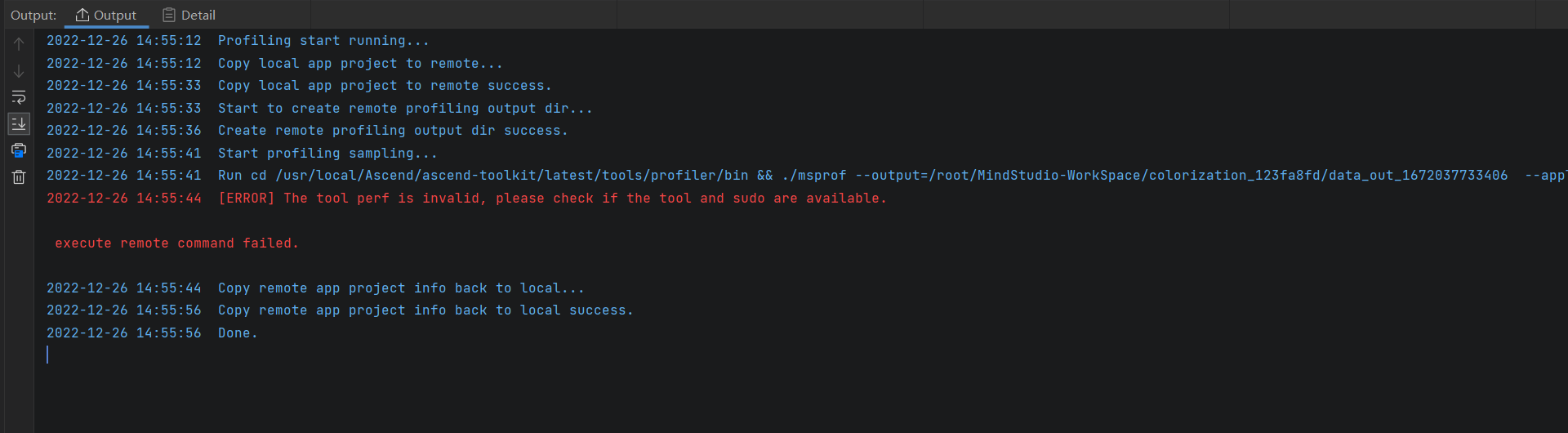
经过排查发现,当选择了API Trace中的OS Runtime API便出现如上问题,取消勾选后,得到如下输出与结果展示
后来查阅文档得知,采集OS Runtime API调用数据需要安装第三方开源工具perf和ltrace,同时配置用户权限。
安装过程为
1 | apt-get install linux-tools-common # pref |
配置用户权限可参考配置用户权限,得到
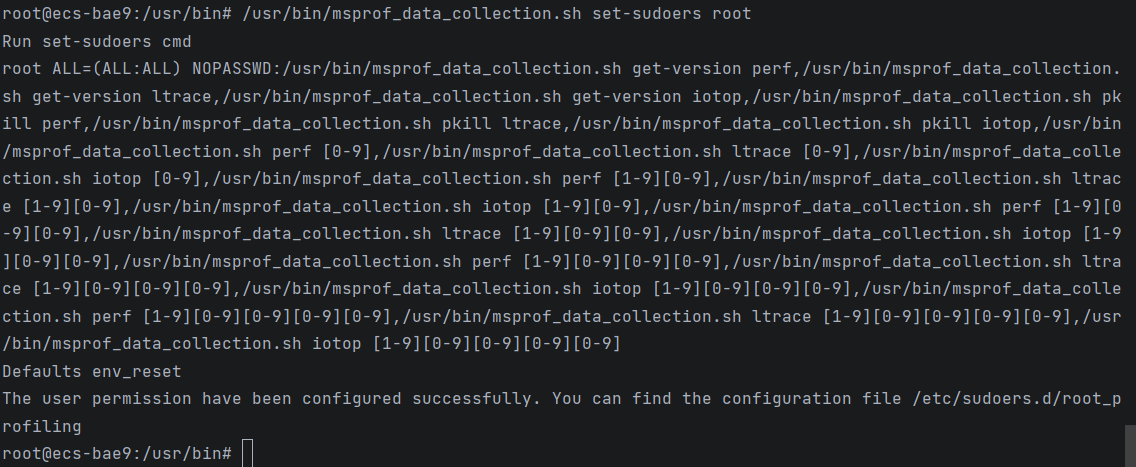
timeline
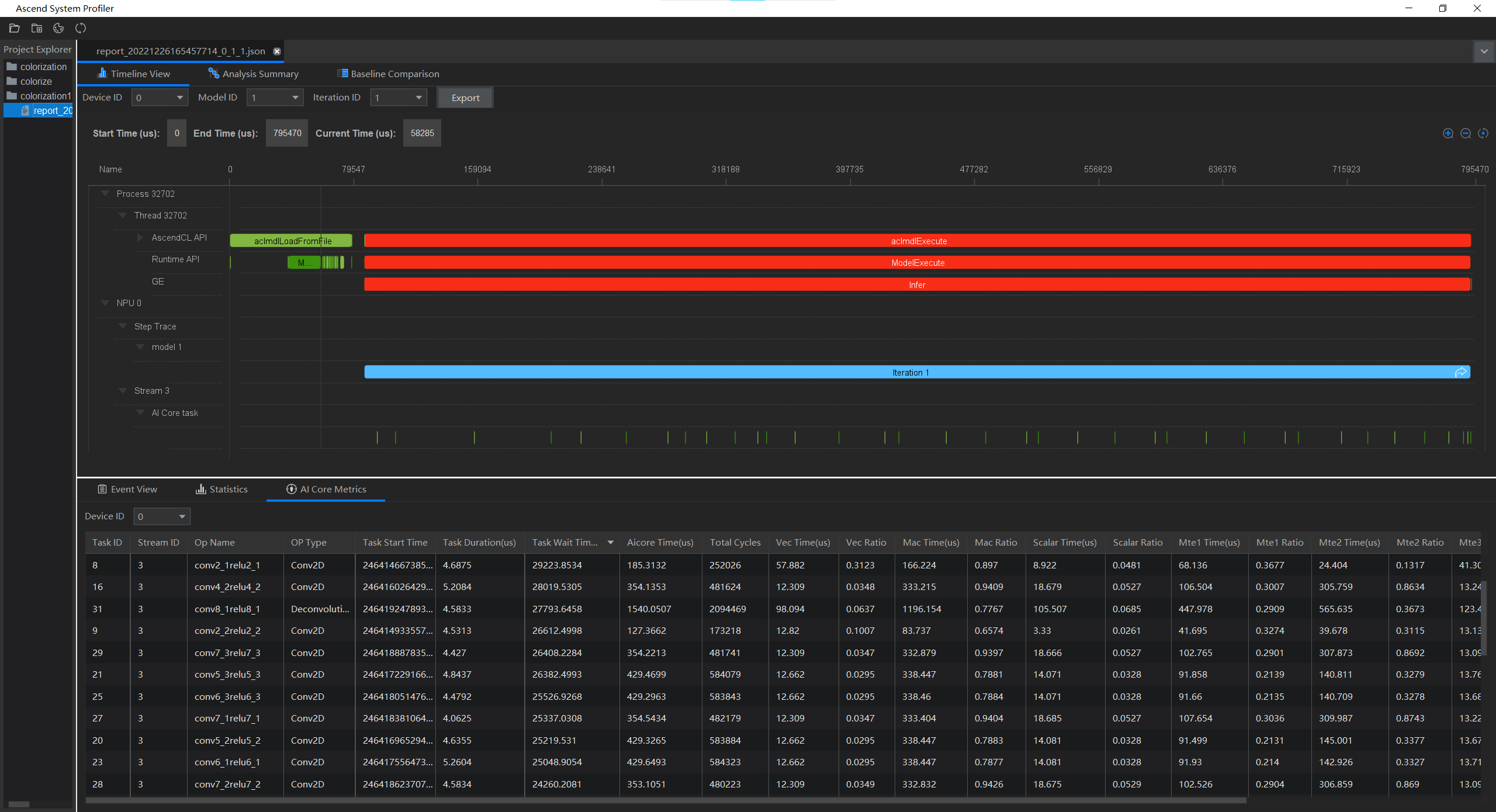
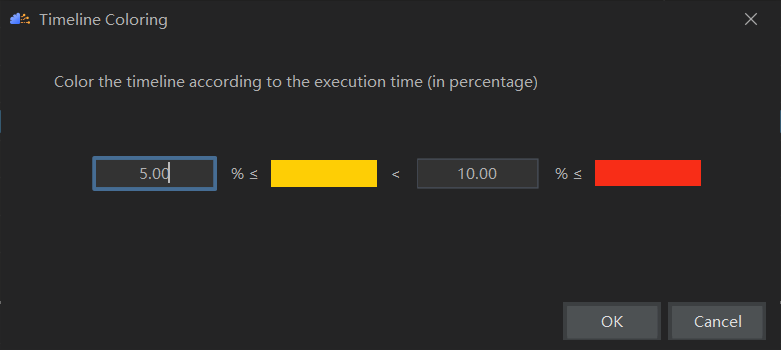
首先可以通过Ascend -> System Profiler -> Timeline Color查看颜色配置,可知耗时占比小于等于5%的时间线显示为绿色,耗时占比在5%~10%的时间线显示为黄色,耗时占比大于等于10%的时间线显示为红色。
Timeline视图中以时间为坐标轴呈现采集的各项数据,上图可知本次采集时间范围为0-795470微秒,采集项有主线程的AscendCL接口耗时数据、Runtime接口耗时数据和GE接口耗时数据,NPU中迭代轨迹数据和AI Core任务数据。从图中可以看出来的接口有ACL模型加载和ACL执行,Rumtime上有模型Copy和执行以及GE上的推理。
Event
右击timeline中标签名可以在Event中看到对应Timeline的顺序执行信息,如ACL的执行顺序和AICore的任务顺序,支持查看的还有Runtime API和 Os Runtime
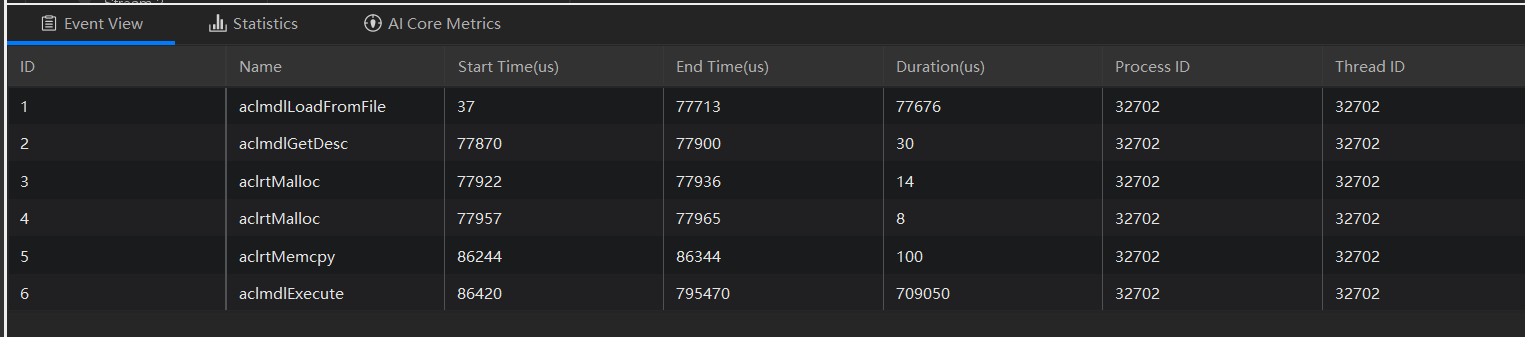
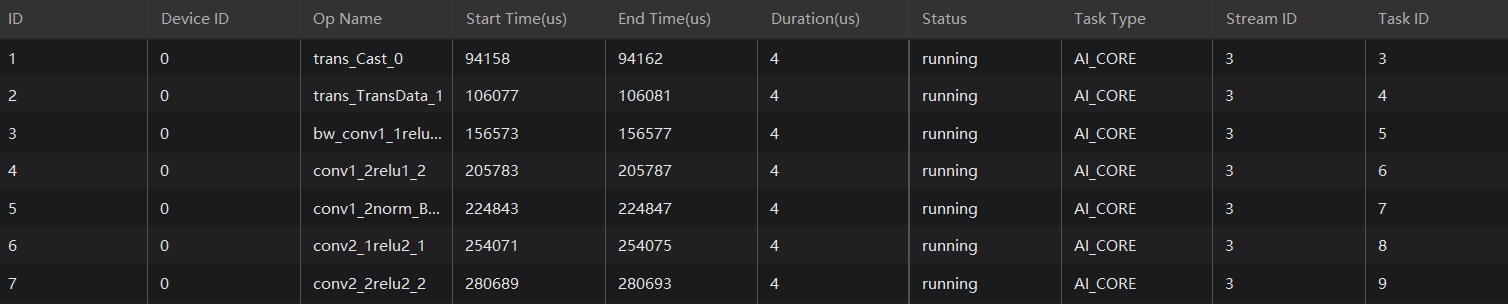
Statistics
通过左上角下拉框选择不同类别的数据,可以查看AscendCL API、OS Runtime API、Runtime API、OPs和Op Info调用情况数据。
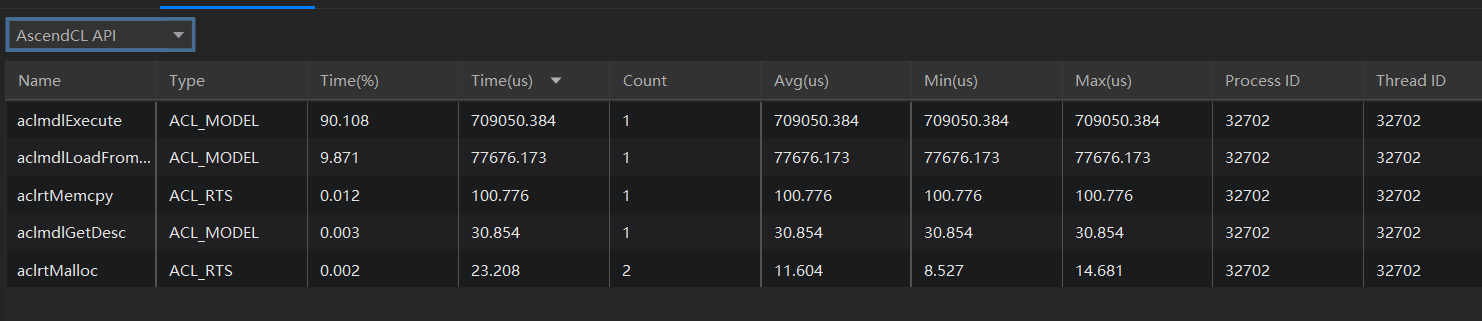
AI Core Metrics
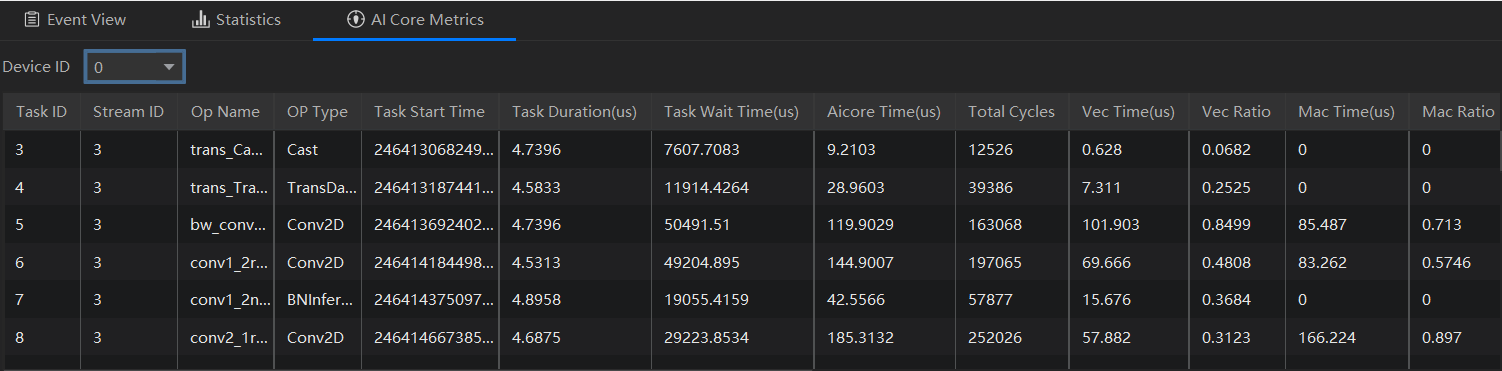
Analysis Summary
Analysis Summary界面分为Analysis Summary和Collection And Platform Info两部分。
- Analysis Summary:展示所有NPU节点通信耗时占比数据,这里没有采集。
- Collection And Platform Info:通过选择需要查看的Device ID后,可以查看对应Device的详细硬件信息和Profiling采集信息。
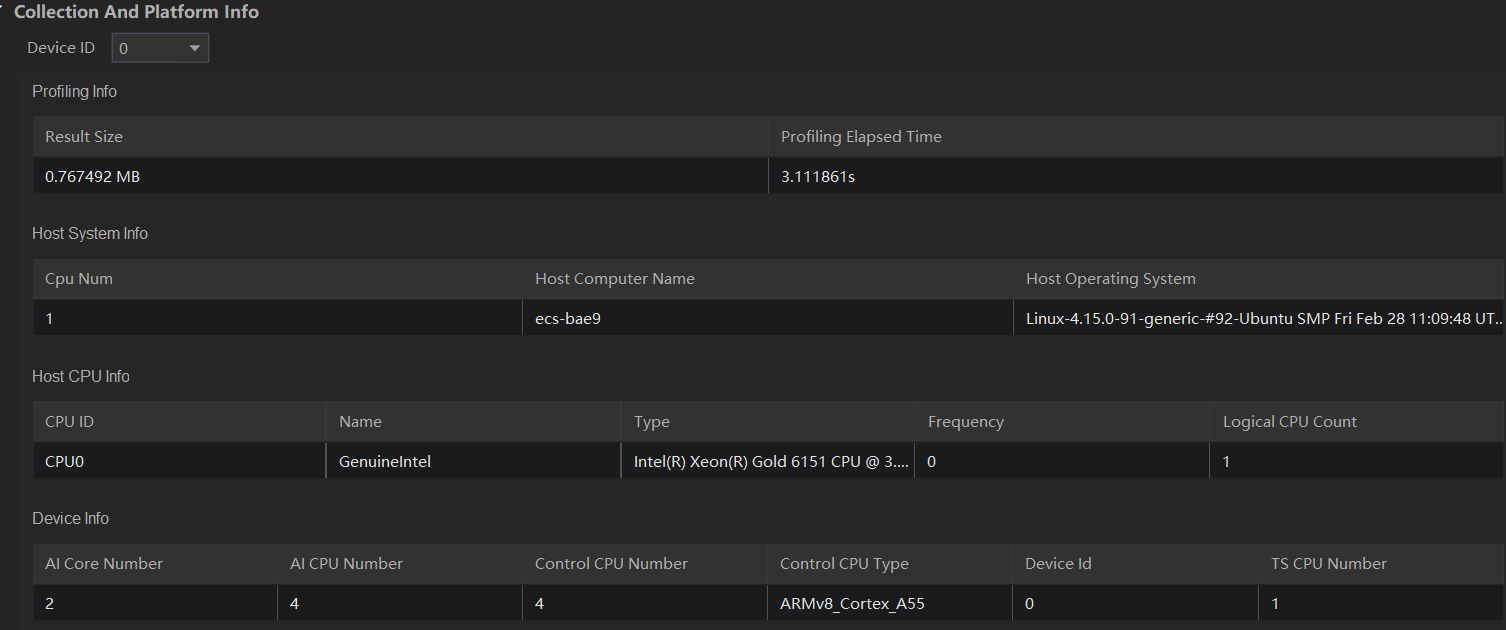
由上图可知,结果文件大小为0.767MB,采集了3秒钟;Host侧有一个CPU操作系统为Ubuntu;CPU型号为Xeon Gold 6151有一个核,主频为3GHz;Device侧有两个AI Core,4个AI CPU和4个控制CPU,DeviceID为0,TS C
Baseline Comparison
Baseline Comparison可以对比两份报告的结果数据,方便在重复执行Profiling产生多个报告后,对比相同情况下多次采集的数据之间的变化情况。
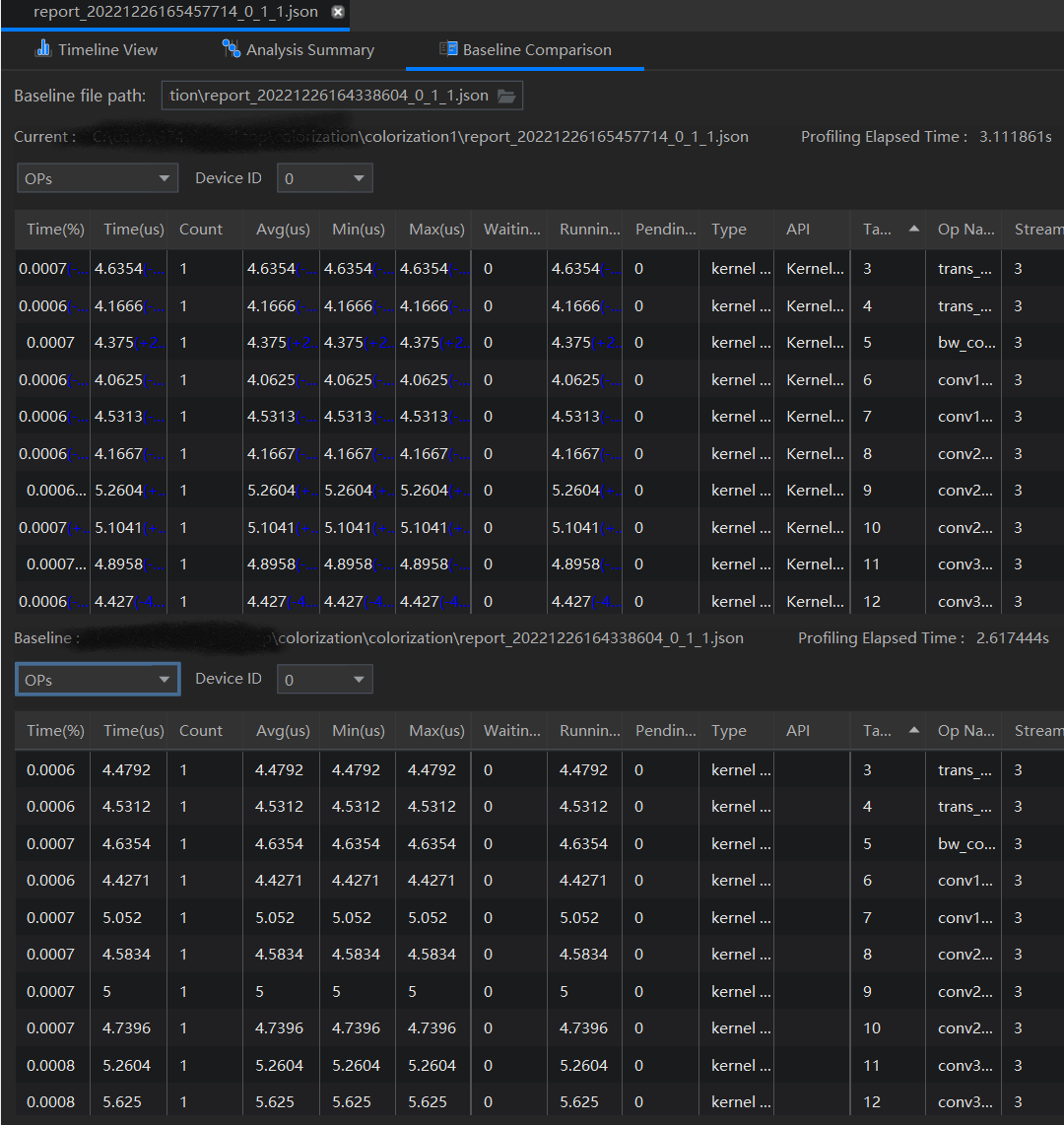
总结
通过使用Profiling工具可以对软硬件性能数据进行采集、分析和汇总展示,找出耗时较长的算子、接口等,为后续有目的性优化提供便利。在本次运行的模型中,发现接口aclmdlExecute执行耗时数值较高,也就是说应用在执行推理的过程中存在耗时长的问题,进一步通过在AI Core Metrics中查看算子执行耗时并按Task Duration算子执行任务的时间从高到低排列,发现各个算子耗时较为均衡,通过优化单个算子可能不太容易提升网络整体性能,接下来可以利用专家系统寻找突破口。
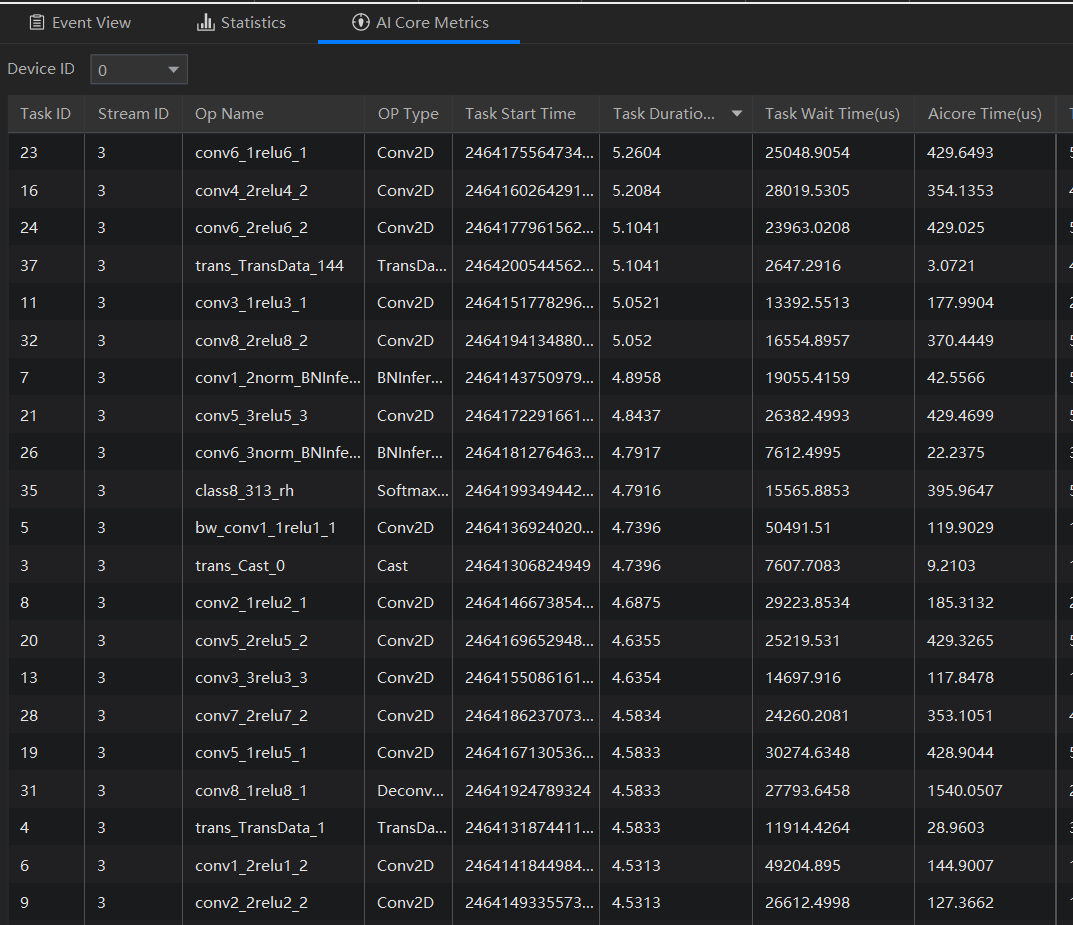
专家系统
专家系统(Advisor)是用于聚焦模型和算子的性能调优TOP问题,识别性能瓶颈Pattern,重点构建模型和算子瓶颈分析并提供优化推荐,支撑开发效率提升的工具。
在MindStudio中通过Ascend->Advisor->Advisor调用,配置各个参数(参数说明详见 配置步骤):
得到分析结果页面,由该页面可知总体性能优劣,Cube吞吐量、Vector吞吐量、AI Core执行时间等等(字段说明详见分析结果展示)
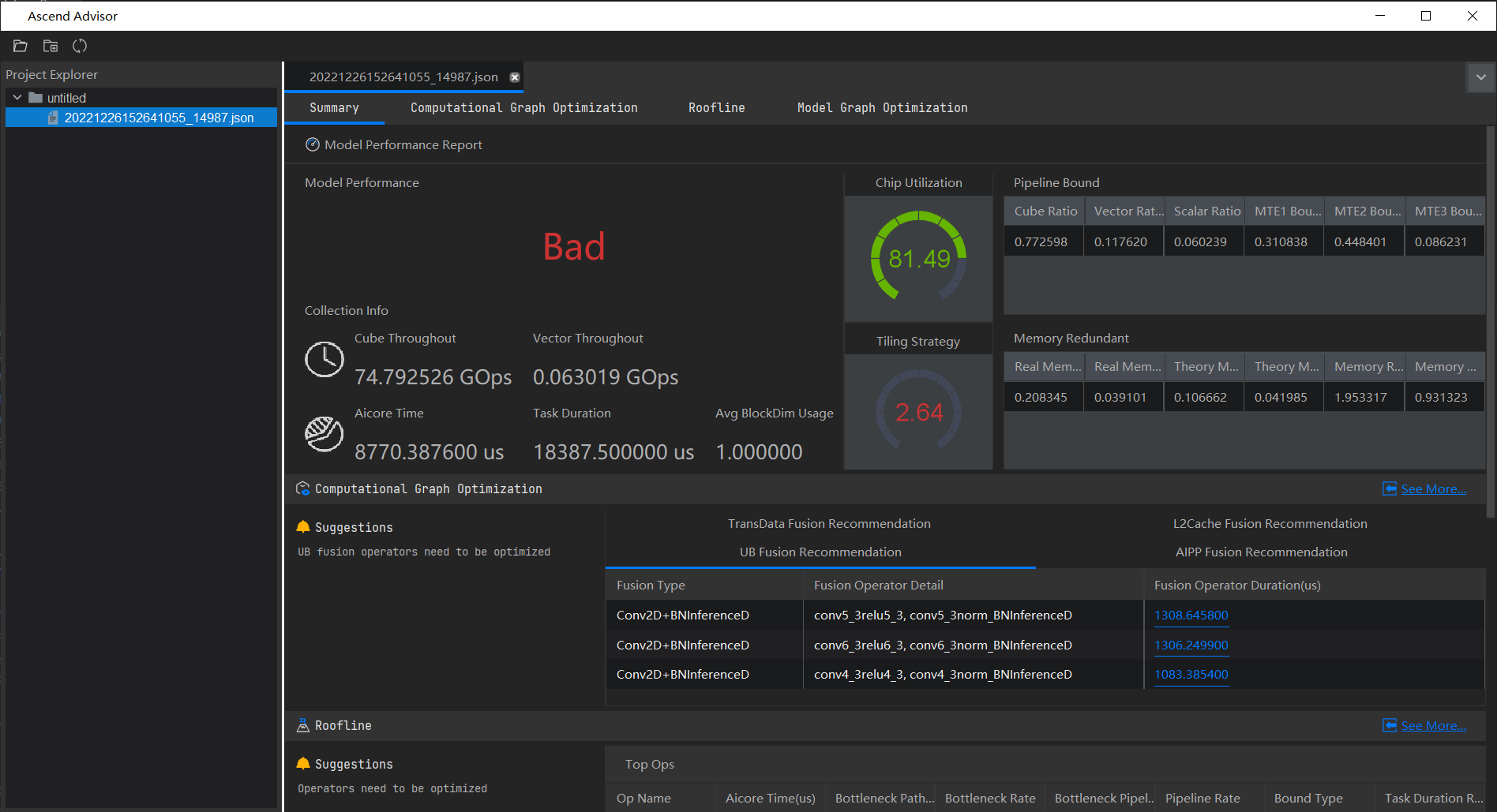
概览页
在该页中,首先可以看到模型整体表现被评价为Bad,收集的信息中,Cube吞吐量为75GOps,AI Core执行时间为8770微秒占整体时间不到二分之一,这也印证了右侧芯片利用率较好,为81.5%,但数据切片策略2.64较低,急需优化。
在流水利用率中,Cube利用率为0.773,Vector利用率为0.117,Scalar利用率为0.060,还有MTE1瓶颈、MTE2瓶颈和MTE3瓶颈。在内存冗余量方面,真实内存读入量为0.208GB,真实内存写出量为0.039GB,理论内存读入量为0.107GB,理论内存写出量为0.042,真实值与理论值存在一定差距,内存读入冗余系数达到了1.95。
计算图优化方面:
- UB融合
有两处可以可以融合的地方,均为卷积+BN操作,每处所占执行时间为1306微秒。 - AIPP融合

可见,专家建议融合Cast+TransData+Conv2D算子。 - TransData算子

Reshape_Ops_Interrupts_Format的优化建议为在不影响精度的情况下尽量避免非连续的操作,使用clone、contiguous将多个非连续操作的组合断开。 - L2融合算子
本次没有给出L2融合的建议
在基于Roofline模型的算子瓶颈识别与优化中给出了前三个算子。
Computational Graph Optimization页面
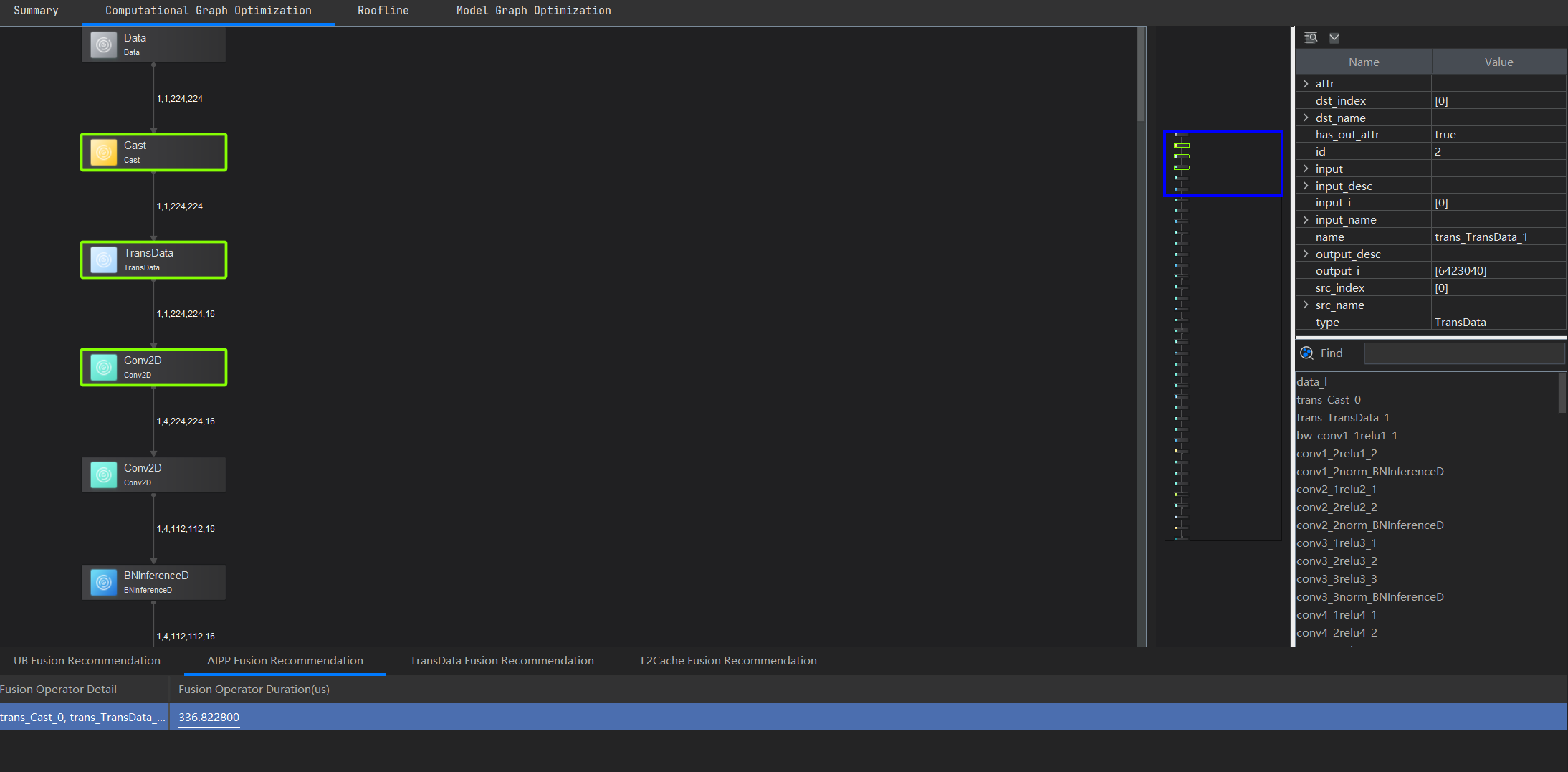
左侧给出了可视化模型,并且对可融合算子进行了高亮显示。右上角给出了算子详细信息,右下角可以搜索模型中的所有算子,下张显示了算子融合的建议。
Roofline页面
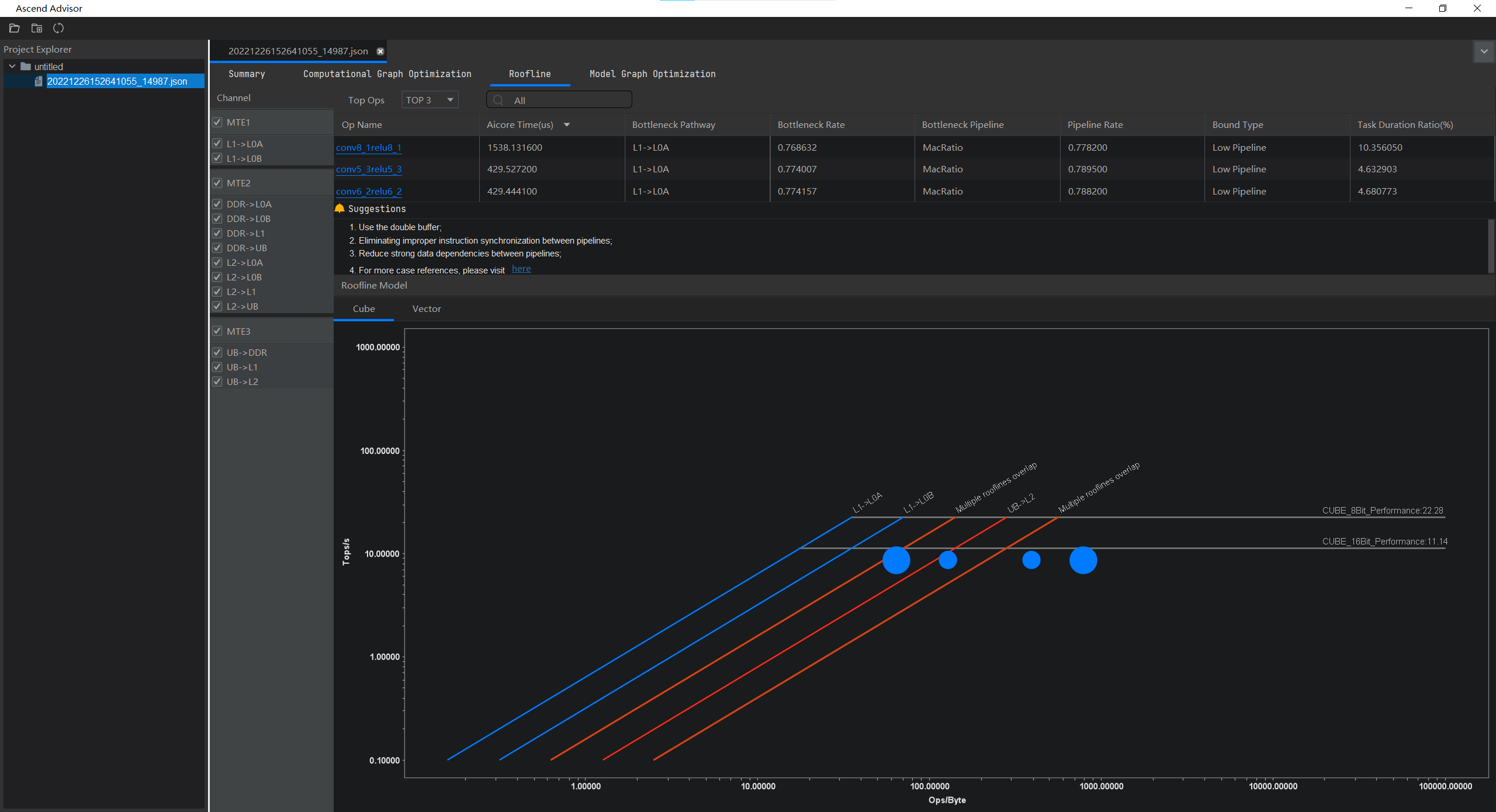
本页面展示了基于Roofline模型的算子瓶颈识别与优化建议功能输出结果。左侧展示专家系统分析结果Roofline模型的Channel通路,每一项对应右下角图中某个工作点的信息。右侧上部展示了TOPN算子信息,点击某个算子下方会展示具体存在瓶颈算子的专家系统建议。下方展示算子分别在Cube和Vector计算单元下的算力情况以及理论算力和带宽。
- 坐标轴中的横坐标单位是Ops/Byte,表示计算强度,每搬运1byte数据可以进行多少次运算,越大表示内存搬运利用率越高。
- 纵坐标单位是Tops/s,表示运算速度,越大表示运算越快。
- 线条转折部分将Roofline模型分成两个部分,斜线部分为Memory Bound(内存限制),横线部分为Compute Bound(计算限制),且实际工作点(图中的彩色点)越靠近对应颜色的斜线,表示Bound越严重,为主要瓶颈所在。
点击AI Core时间最长的算子,得到
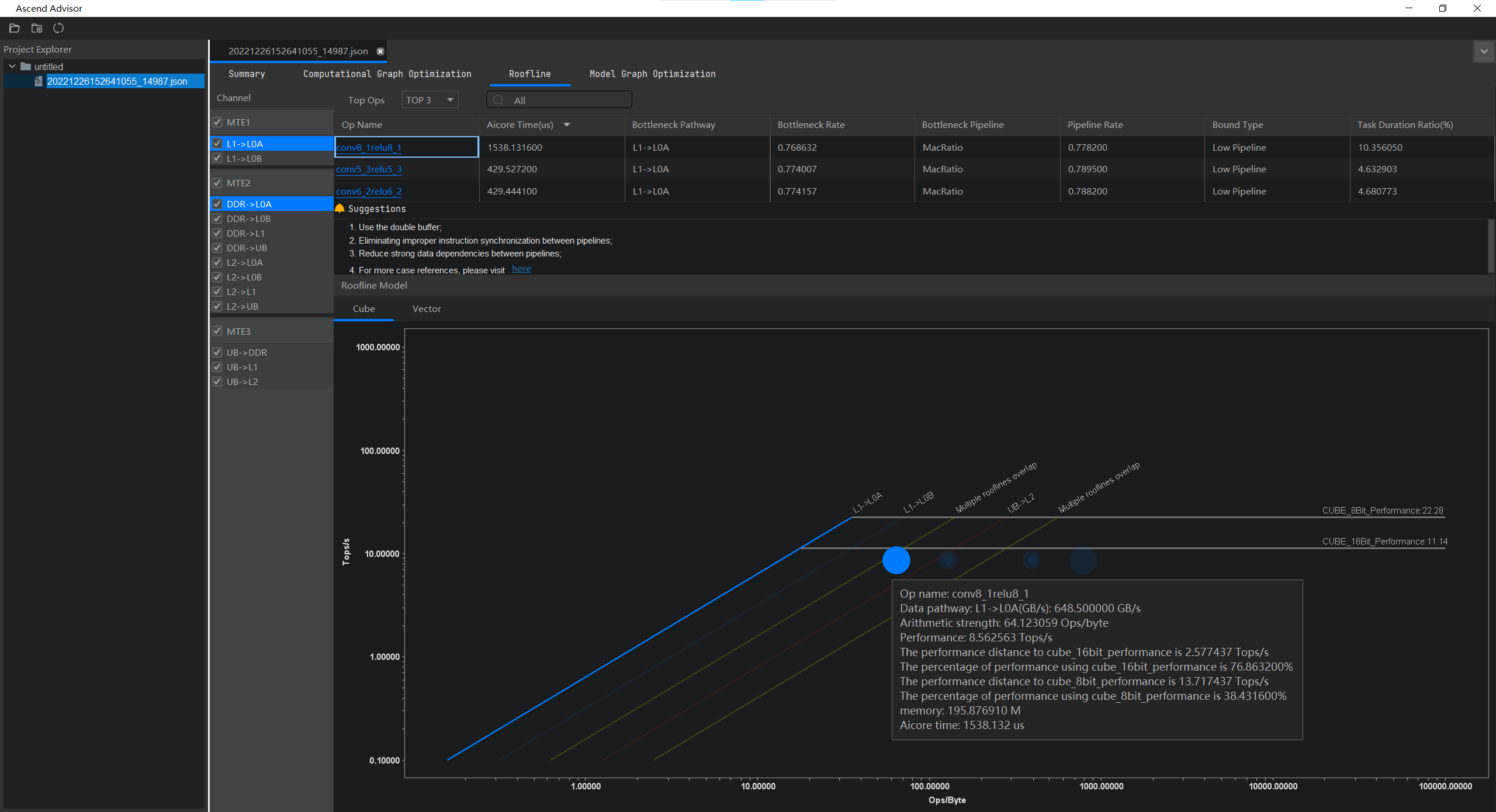
对于该模型,TOP10算子均为L1->L0A数据通路,
Model Graph Optimization页面
本界面应当输出基于Timeline的AICPU算子优化功能结果,但专家系统没有对本模型输出信息。
总结
本节利用专家系统对模型性能瓶颈进行了分析,找出了可以融合的UB算子和首层AIPP算子,对TransData算子进行了识别,后续可以根据专家系统的建议手动优化相关算子,但由于笔者没有相关的知识储备还无法进行优化工作。在此希望昇腾可以推出与算子融合、图融合相关的教程。关于文档中提及的性能调优一键式闭环功能,目前仅提供基于ONNX的改图及调优参考,
总结
本次通过学习利用MindStudio体验了昇腾AI开发流程,体会到了昇腾生态在AI部署方面具有的特点与优势,也感受到了算子是如何实现深度学习程序的,AscendCL和pipeline两种开发模式具有各自的特点与长处。在操作过程中通过利用开发文档解决了遇到的种种困难,最开始由于对toolchain、ssh、deployment三者之间的路径关系不甚了解,造成了编译同步地址与自己设置的deployment存在差异,找不到编译后文件的情况。
在操作Mindstudio遇到了两点问题,希望Mindstudio后期能对性能方面进行优化。
-
Mindstudio太占用资源
在实操过程中,Mindstudio在执行解析操作时CPU使用率经常达到95%以上(i7-9750H),相较于其他常用IDE资源占用较多。 -
Mindstudio经常出现界面卡死
多次遇到界面卡死现象,较多出现在转为Ascend工程时的窗口重载过程、deployment同步文件、生成pipeline可视图以及一些对模型的解析过程。

