
【MindStudio训练营第一季】Profiler
Profiling简介
Profiling性能分析工具用于采集和分析运行在昇腾AI处理器上的推理业务(应用或算子)各个运行阶段的关键性能指标,可根据输出的性能数据针对关键性能瓶颈做出优化以实现产品的极致性能。
Profiling性能分析工具针对APP工程运行过程中的硬件和软件以及Host侧性能数据进行采集、分析并汇总展示:
- 硬件的性能数据包括:AI Core等模块的PMU指标及系统硬件性能指标。
- 软件的性能数据包括:AscendCL、GE、RTS等模块的性能指标数据。
- Host侧性能数据包括:CPU、Memory、Disk、Network、pthread和system call模块的性能指标数据。
Profiling还可以采集Host与Device之间、Device间的同步异步内存复制时延,在AscendCL和Runtime接口数据中体现。
Profiling的部分

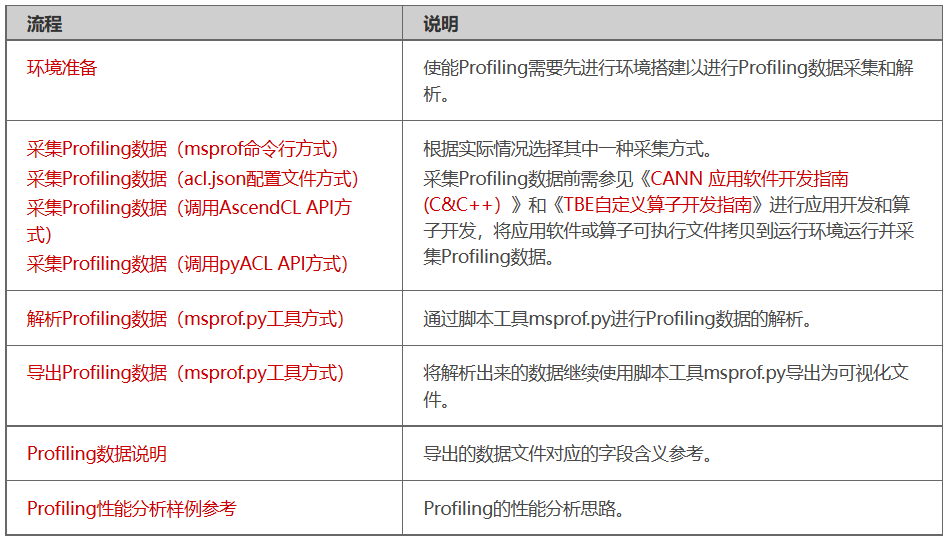
调优步骤
调优主要分为三步
- 性能数据采集、解析、分析
- 性能问题定位,发现性能瓶颈点
- 采取性能优化措施
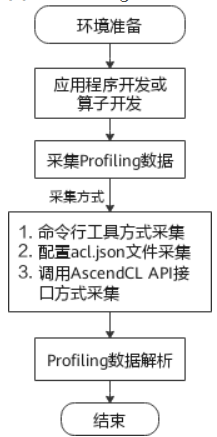
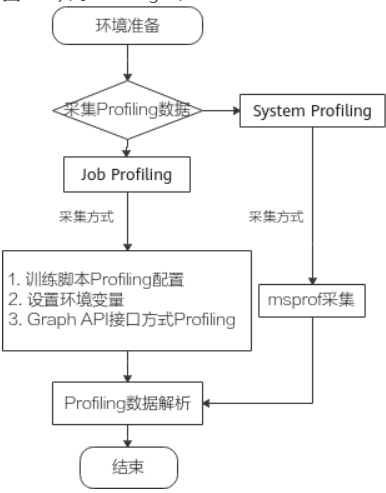
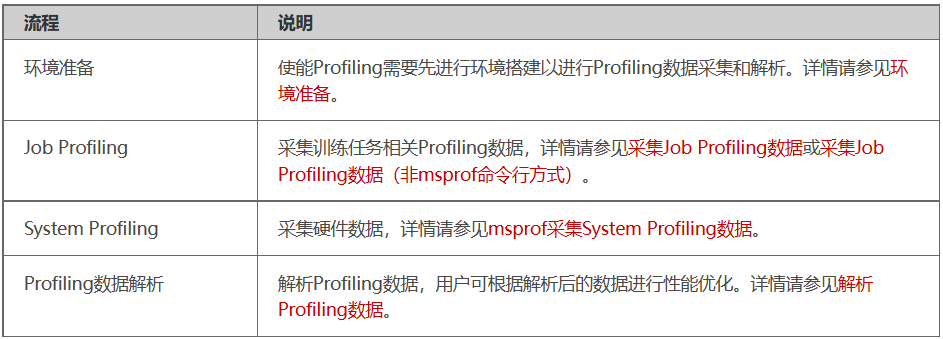
Profiling流程
-
推理
-
训练
数据采集方式
- 推理场景
- msprof命令行方式
- acl.json配置文件方式
- 调用AscendCL API方式
- 调用pyACL API方式
- 训练场景
- msprof命令行方式
- Ascend Graph开发方式
- 环境变量方式
- 训练脚本方式
注意:同时启用多种采集方式时,有且仅有一种使能方式可以生效。但为了避免不必要的错误,不建议同时使用多种不同的采集方式。
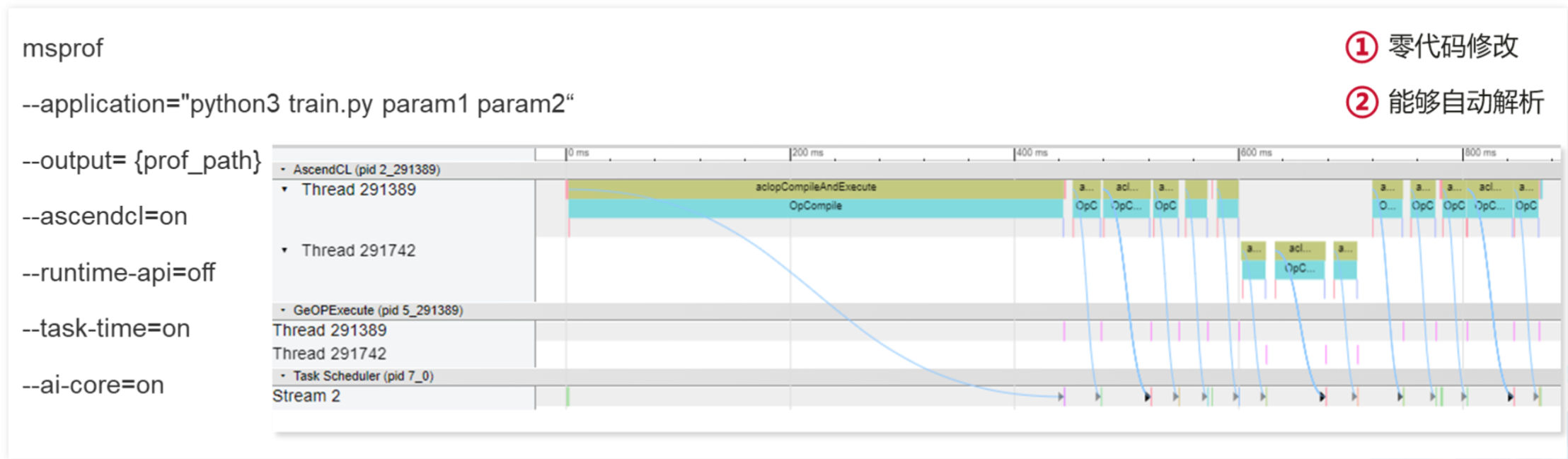
msprof命令行
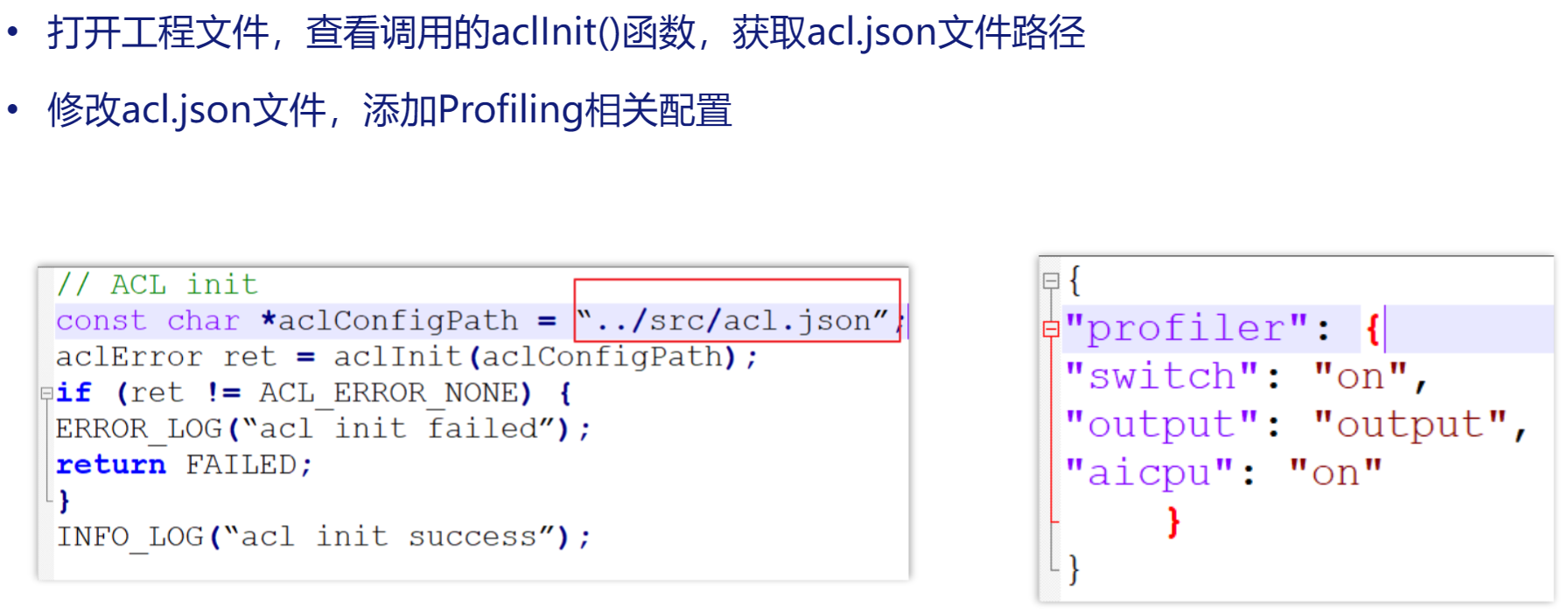
acl.json
API接口


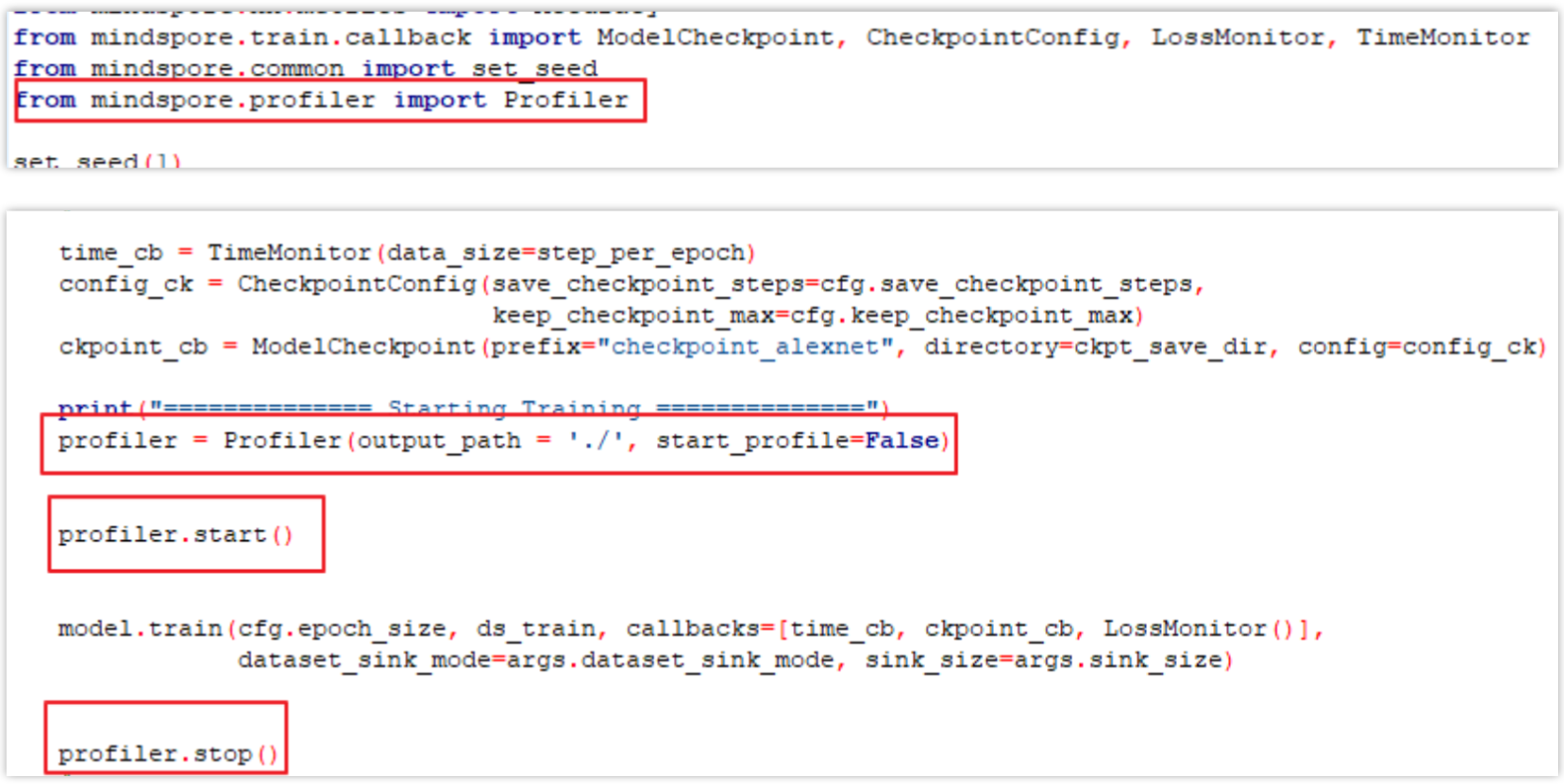
Mindspore
环境变量设置和脚本设置
-
TensorFlow

-
PyTorch侧
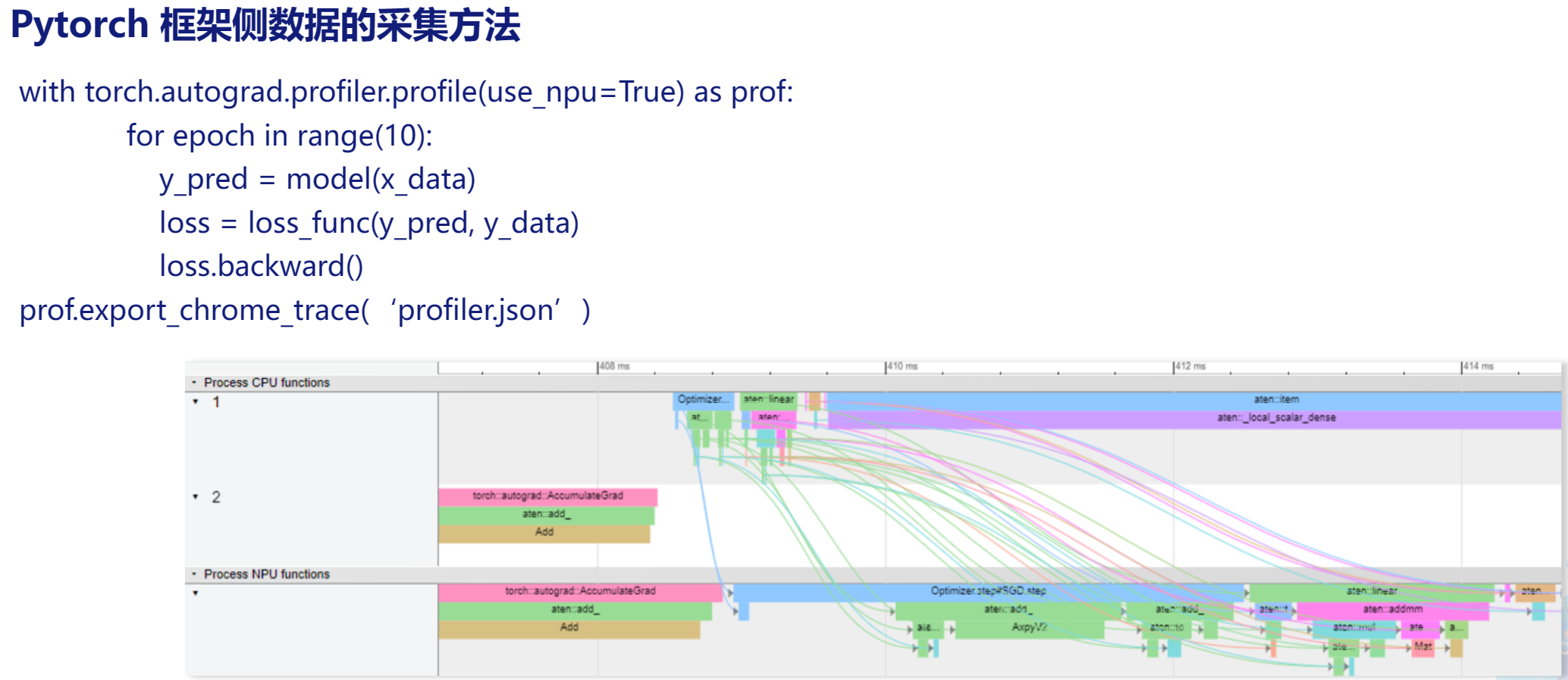
-
CANN侧
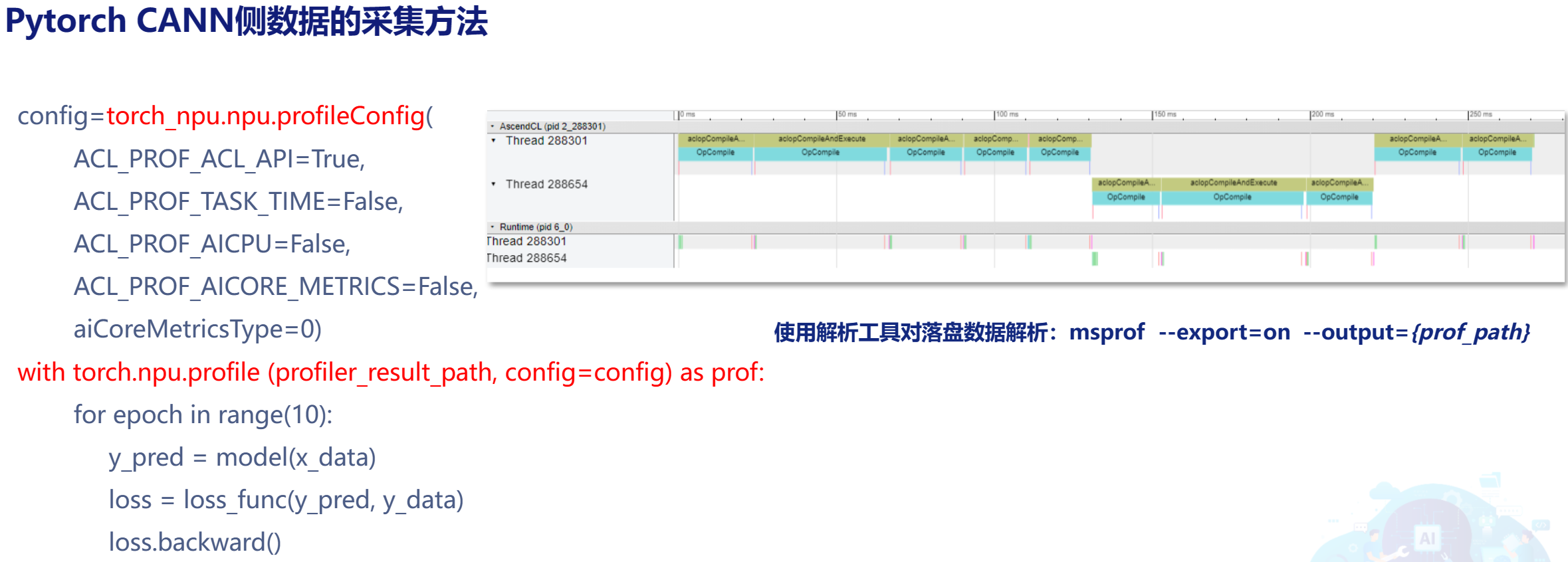
-
PyTorch侧和CANN侧

采集epoch耗时
- 对比不同epoch
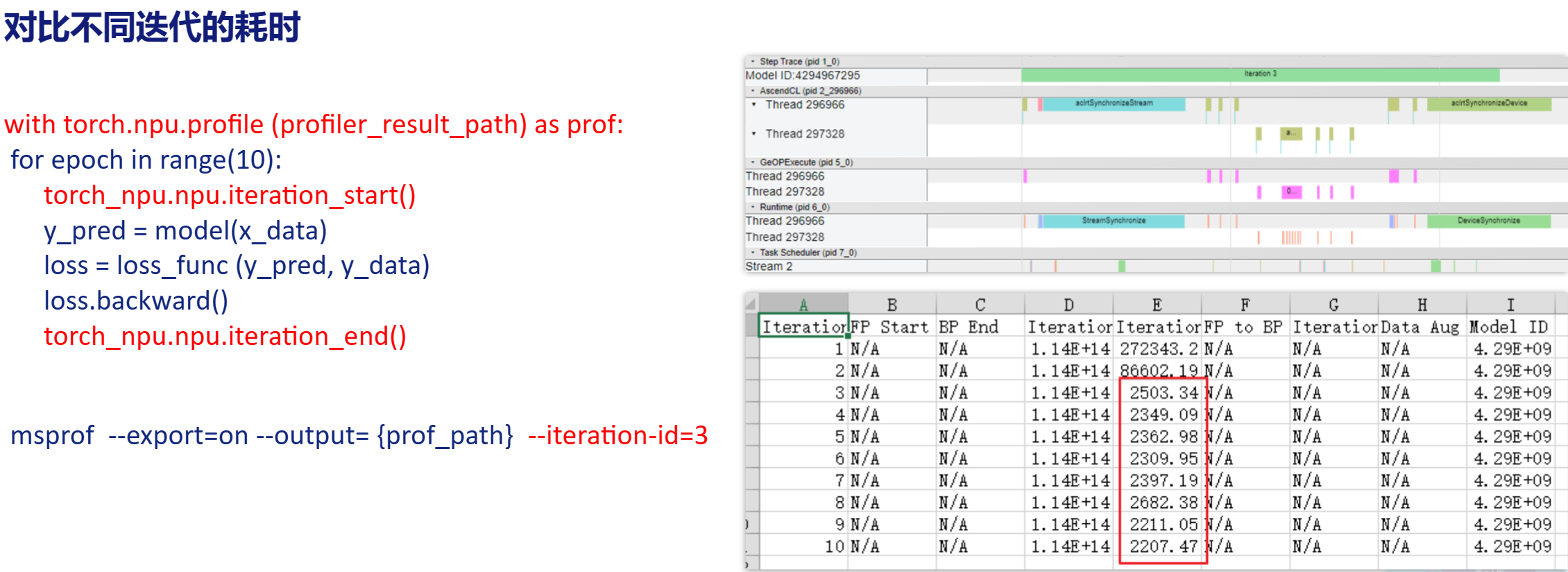
- 仅采集需要的epoch

数据说明
step trace timeline

step trace timeline of epoch

HCCL timeline

组件接口耗时

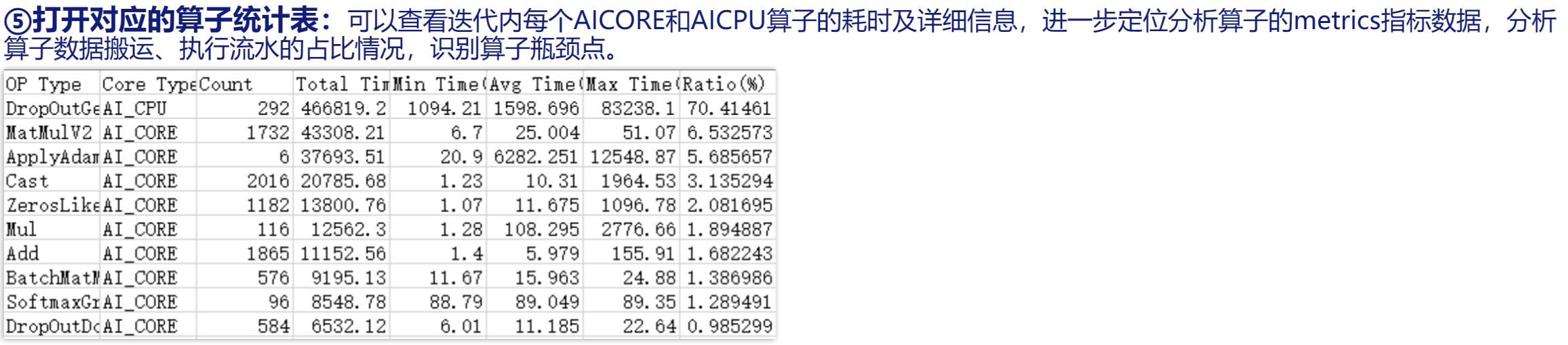
算子统计表
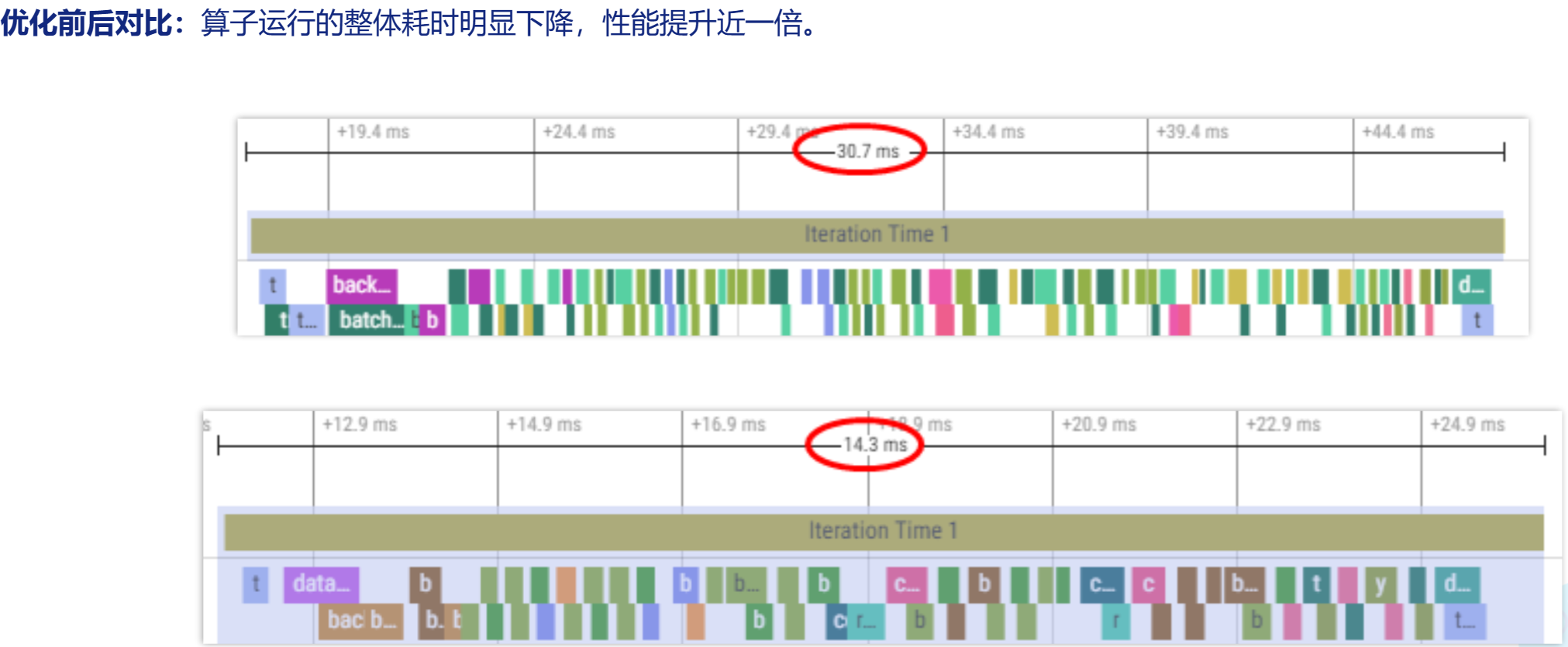
算子融合优化
在整网性能调优过程中,通过算子融合的方式,将算子融合后,调度到Aicore上执行,减少数据的搬运,提升整网性能。
例如,对于网络结构中大量的Conv2D+BN+SCALE算子,开启算子融合后融合为Conv2D算子,采集性能数据进行对比。
总结
本文简要介绍了使用Profiling工具分析模型的性能,这里包含MsprofTX、AscendCL、Ge、Runtime、AI CPU和TaskScheduler五个层次,可以通过Profiling查看耗时较长的接口和算子,可以通过算子融合提升整网性能。
Profiling也支持多卡场景下的性能分析进行集群优化。
相关推荐

评论
