
【CANN训练营第三季】【预备2】StarGAN
背景
StarGAN是发表于CVPR 2018是的一个工作,主要解决多域图像转换的问题。
之前的Pix2Pix和CycleGAN解决了两个域之间基于匹配数据和非匹配数据的转换,但在实际应用中需要多个域之间的相互转换,这就需要训练多个生成器,而StarGAN使用一个生成器实现了多个域的转换。
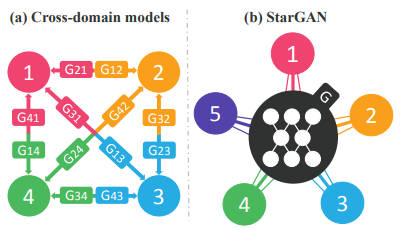
创新点
- 在输入侧加入了域信息,可以只使用一个生成器和判别器来uexi多个域之间的映射,并从所有域的图像中进行训练。
- 通过加入掩码向量的方法实现了多个数据集之间的多域图像转换。
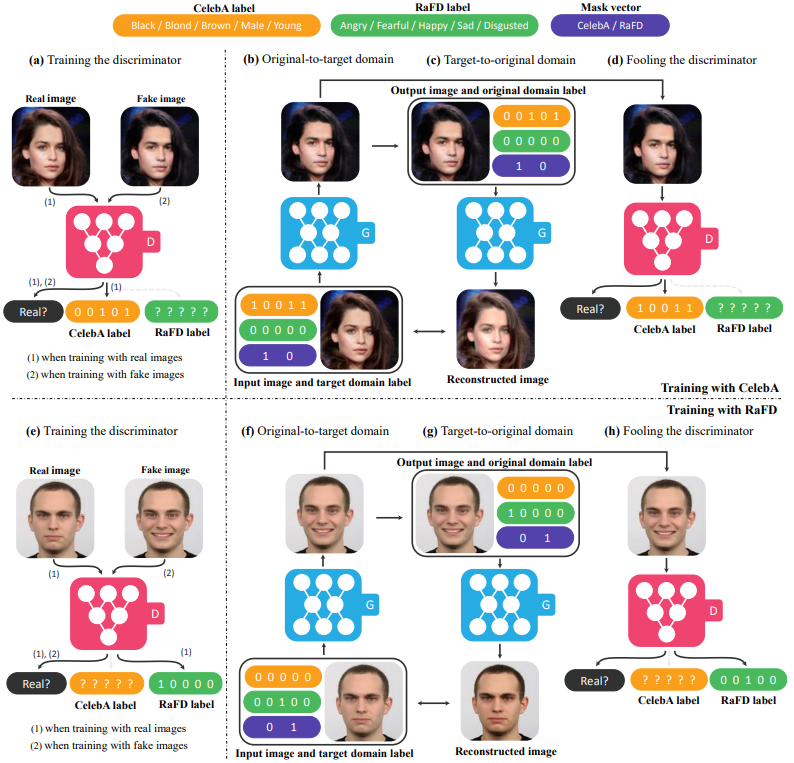
网络模型
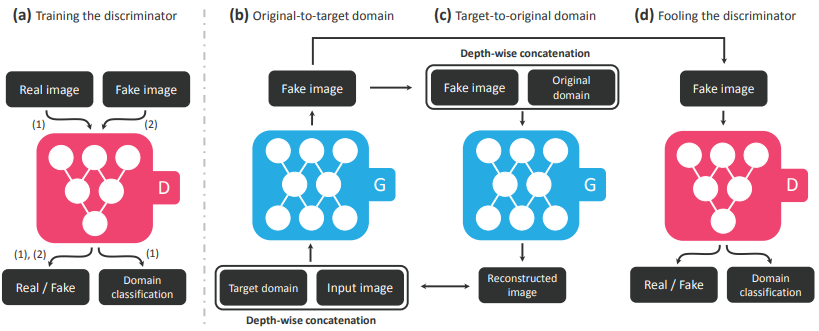
处理流程为:
- 将图像与目标生成域输入到生成网络G中合成fake图片;
- 将fake图片和真实图片输入到判别器D中判断来自哪个域;
- 一致性约束,要求将生成的fake图片和原始图片的域信息通过生成器G输出重建的原始输入图片
网络结构
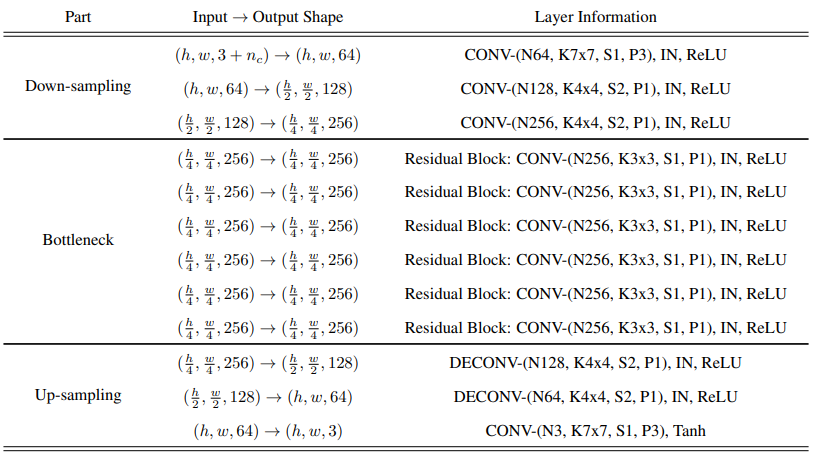
生成器网络结构
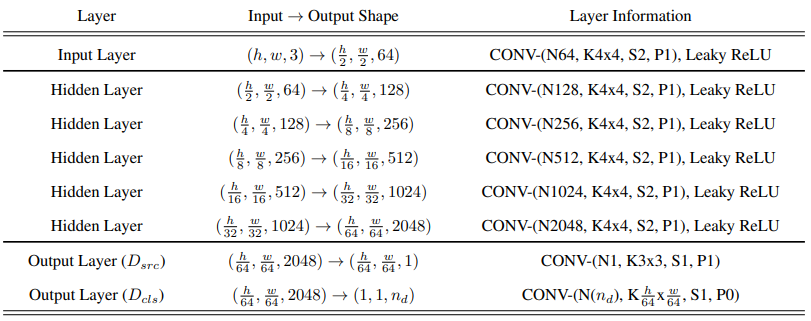
判别器网络结构,采用PatchGAN结构,对局部图像块进行真假分类
损失函数
- 对抗损失
判别器能否分类真实图像和生成图像
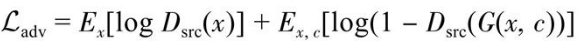
- 域分类损失
starGAN在判别器的顶部引入了一个复杂的辅助分类器。判别器的训练目标为将真实图像的域分类损失最小化,以学习真实图像的正确分类;生成器的训练目标为将生成图像的域分类损失最小化,使得生成的图像能够被分类为目标域。
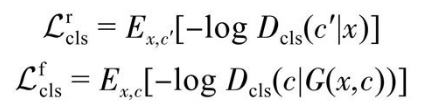
- 重构损失
确保生成的数据能够很好地还原到本来的领域分类中。
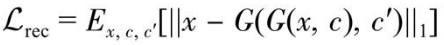
生成器与判别器损失
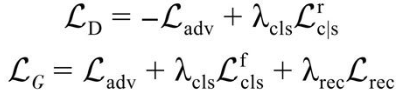
实验结果
训练过程
CelebA数据集

代码
-
生成器
先对模型降维缩小为原来4倍,再使用多个残差网络获得等维度输出,接着使用转置卷积放大4倍,最后通过一层尺寸不变的卷积,取tanh作为输出。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54class Generator(nn.Module):
"""Generator network."""
def __init__(self, conv_dim=64, c_dim=5, repeat_num=6):
super(Generator, self).__init__()
layers = []
layers.append(nn.Conv2d(3+c_dim, conv_dim, kernel_size=7, stride=1, padding=3, bias=False))
layers.append(nn.InstanceNorm2d(conv_dim, affine=True, track_running_stats=True))
layers.append(nn.ReLU(inplace=True))
# Down-sampling layers.
curr_dim = conv_dim
for i in range(2):
layers.append(nn.Conv2d(curr_dim, curr_dim*2, kernel_size=4, stride=2, padding=1, bias=False))
layers.append(nn.InstanceNorm2d(curr_dim*2, affine=True, track_running_stats=True))
layers.append(nn.ReLU(inplace=True))
curr_dim = curr_dim * 2
# Bottleneck layers.
for i in range(repeat_num):
layers.append(ResidualBlock(dim_in=curr_dim, dim_out=curr_dim))
# Up-sampling layers.
for i in range(2):
layers.append(nn.ConvTranspose2d(curr_dim, curr_dim//2, kernel_size=4, stride=2, padding=1, bias=False))
layers.append(nn.InstanceNorm2d(curr_dim//2, affine=True, track_running_stats=True))
layers.append(nn.ReLU(inplace=True))
curr_dim = curr_dim // 2
layers.append(nn.Conv2d(curr_dim, 3, kernel_size=7, stride=1, padding=3, bias=False))
layers.append(nn.Tanh())
self.main = nn.Sequential(*layers)
def forward(self, x, c):
# Replicate spatially and concatenate domain information.
# Note that this type of label conditioning does not work at all if we use reflection padding in Conv2d.
# This is because instance normalization ignores the shifting (or bias) effect.
c = c.view(c.size(0), c.size(1), 1, 1)
c = c.repeat(1, 1, x.size(2), x.size(3))
x = torch.cat([x, c], dim=1)
return self.main(x)
class ResidualBlock(nn.Module):
"""Residual Block with instance normalization."""
def __init__(self, dim_in, dim_out):
super(ResidualBlock, self).__init__()
self.main = nn.Sequential(
nn.Conv2d(dim_in, dim_out, kernel_size=3, stride=1, padding=1, bias=False),
nn.InstanceNorm2d(dim_out, affine=True, track_running_stats=True),
nn.ReLU(inplace=True),
nn.Conv2d(dim_out, dim_out, kernel_size=3, stride=1, padding=1, bias=False),
nn.InstanceNorm2d(dim_out, affine=True, track_running_stats=True))
def forward(self, x):
return x + self.main(x) -
判别器
判别器输出两个,前者表示输出代表域的预测概率,后者判断图片是否为真。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24class Discriminator(nn.Module):
"""Discriminator network with PatchGAN."""
def __init__(self, image_size=128, conv_dim=64, c_dim=5, repeat_num=6):
super(Discriminator, self).__init__()
layers = []
layers.append(nn.Conv2d(3, conv_dim, kernel_size=4, stride=2, padding=1))
layers.append(nn.LeakyReLU(0.01))
curr_dim = conv_dim
for i in range(1, repeat_num):
layers.append(nn.Conv2d(curr_dim, curr_dim*2, kernel_size=4, stride=2, padding=1))
layers.append(nn.LeakyReLU(0.01))
curr_dim = curr_dim * 2
kernel_size = int(image_size / np.power(2, repeat_num))
self.main = nn.Sequential(*layers)
self.conv1 = nn.Conv2d(curr_dim, 1, kernel_size=3, stride=1, padding=1, bias=False)
self.conv2 = nn.Conv2d(curr_dim, c_dim, kernel_size=kernel_size, bias=False)
def forward(self, x):
h = self.main(x)
out_src = self.conv1(h)
out_cls = self.conv2(h)
return out_src, out_cls.view(out_cls.size(0), out_cls.size(1)) -
多数据集训练
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181def train_multi(self):
"""Train StarGAN with multiple datasets."""
# Data iterators.
celeba_iter = iter(self.celeba_loader)
rafd_iter = iter(self.rafd_loader)
# Fetch fixed inputs for debugging.
x_fixed, c_org = next(celeba_iter)
x_fixed = x_fixed.to(self.device)
c_celeba_list = self.create_labels(c_org, self.c_dim, 'CelebA', self.selected_attrs)
c_rafd_list = self.create_labels(c_org, self.c2_dim, 'RaFD')
zero_celeba = torch.zeros(x_fixed.size(0), self.c_dim).to(self.device) # Zero vector for CelebA.
zero_rafd = torch.zeros(x_fixed.size(0), self.c2_dim).to(self.device) # Zero vector for RaFD.
mask_celeba = self.label2onehot(torch.zeros(x_fixed.size(0)), 2).to(self.device) # Mask vector: [1, 0].
mask_rafd = self.label2onehot(torch.ones(x_fixed.size(0)), 2).to(self.device) # Mask vector: [0, 1].
# Learning rate cache for decaying.
g_lr = self.g_lr
d_lr = self.d_lr
# Start training from scratch or resume training.
start_iters = 0
if self.resume_iters:
start_iters = self.resume_iters
self.restore_model(self.resume_iters)
# Start training.
print('Start training...')
start_time = time.time()
for i in range(start_iters, self.num_iters):
for dataset in ['CelebA', 'RaFD']:
# =================================================================================== #
# 1. Preprocess input data #
# =================================================================================== #
# Fetch real images and labels.
data_iter = celeba_iter if dataset == 'CelebA' else rafd_iter
try:
x_real, label_org = next(data_iter)
except:
if dataset == 'CelebA':
celeba_iter = iter(self.celeba_loader)
x_real, label_org = next(celeba_iter)
elif dataset == 'RaFD':
rafd_iter = iter(self.rafd_loader)
x_real, label_org = next(rafd_iter)
# Generate target domain labels randomly.
rand_idx = torch.randperm(label_org.size(0))
label_trg = label_org[rand_idx]
if dataset == 'CelebA':
c_org = label_org.clone()
c_trg = label_trg.clone()
zero = torch.zeros(x_real.size(0), self.c2_dim)
mask = self.label2onehot(torch.zeros(x_real.size(0)), 2)
c_org = torch.cat([c_org, zero, mask], dim=1)
c_trg = torch.cat([c_trg, zero, mask], dim=1)
elif dataset == 'RaFD':
c_org = self.label2onehot(label_org, self.c2_dim)
c_trg = self.label2onehot(label_trg, self.c2_dim)
zero = torch.zeros(x_real.size(0), self.c_dim)
mask = self.label2onehot(torch.ones(x_real.size(0)), 2)
c_org = torch.cat([zero, c_org, mask], dim=1)
c_trg = torch.cat([zero, c_trg, mask], dim=1)
x_real = x_real.to(self.device) # Input images.
c_org = c_org.to(self.device) # Original domain labels.
c_trg = c_trg.to(self.device) # Target domain labels.
label_org = label_org.to(self.device) # Labels for computing classification loss.
label_trg = label_trg.to(self.device) # Labels for computing classification loss.
# =================================================================================== #
# 2. Train the discriminator #
# =================================================================================== #
# Compute loss with real images.
out_src, out_cls = self.D(x_real)
out_cls = out_cls[:, :self.c_dim] if dataset == 'CelebA' else out_cls[:, self.c_dim:]
d_loss_real = - torch.mean(out_src)
d_loss_cls = self.classification_loss(out_cls, label_org, dataset)
# Compute loss with fake images.
x_fake = self.G(x_real, c_trg)
out_src, _ = self.D(x_fake.detach())
d_loss_fake = torch.mean(out_src)
# Compute loss for gradient penalty.
alpha = torch.rand(x_real.size(0), 1, 1, 1).to(self.device)
x_hat = (alpha * x_real.data + (1 - alpha) * x_fake.data).requires_grad_(True)
out_src, _ = self.D(x_hat)
d_loss_gp = self.gradient_penalty(out_src, x_hat)
# Backward and optimize.
d_loss = d_loss_real + d_loss_fake + self.lambda_cls * d_loss_cls + self.lambda_gp * d_loss_gp
self.reset_grad()
d_loss.backward()
self.d_optimizer.step()
# Logging.
loss = {}
loss['D/loss_real'] = d_loss_real.item()
loss['D/loss_fake'] = d_loss_fake.item()
loss['D/loss_cls'] = d_loss_cls.item()
loss['D/loss_gp'] = d_loss_gp.item()
# =================================================================================== #
# 3. Train the generator #
# =================================================================================== #
if (i+1) % self.n_critic == 0:
# Original-to-target domain.
x_fake = self.G(x_real, c_trg)
out_src, out_cls = self.D(x_fake)
out_cls = out_cls[:, :self.c_dim] if dataset == 'CelebA' else out_cls[:, self.c_dim:]
g_loss_fake = - torch.mean(out_src)
g_loss_cls = self.classification_loss(out_cls, label_trg, dataset)
# Target-to-original domain.
x_reconst = self.G(x_fake, c_org)
g_loss_rec = torch.mean(torch.abs(x_real - x_reconst))
# Backward and optimize.
g_loss = g_loss_fake + self.lambda_rec * g_loss_rec + self.lambda_cls * g_loss_cls
self.reset_grad()
g_loss.backward()
self.g_optimizer.step()
# Logging.
loss['G/loss_fake'] = g_loss_fake.item()
loss['G/loss_rec'] = g_loss_rec.item()
loss['G/loss_cls'] = g_loss_cls.item()
# =================================================================================== #
# 4. Miscellaneous #
# =================================================================================== #
# Print out training info.
if (i+1) % self.log_step == 0:
et = time.time() - start_time
et = str(datetime.timedelta(seconds=et))[:-7]
log = "Elapsed [{}], Iteration [{}/{}], Dataset [{}]".format(et, i+1, self.num_iters, dataset)
for tag, value in loss.items():
log += ", {}: {:.4f}".format(tag, value)
print(log)
if self.use_tensorboard:
for tag, value in loss.items():
self.logger.scalar_summary(tag, value, i+1)
# Translate fixed images for debugging.
if (i+1) % self.sample_step == 0:
with torch.no_grad():
x_fake_list = [x_fixed]
for c_fixed in c_celeba_list:
c_trg = torch.cat([c_fixed, zero_rafd, mask_celeba], dim=1)
x_fake_list.append(self.G(x_fixed, c_trg))
for c_fixed in c_rafd_list:
c_trg = torch.cat([zero_celeba, c_fixed, mask_rafd], dim=1)
x_fake_list.append(self.G(x_fixed, c_trg))
x_concat = torch.cat(x_fake_list, dim=3)
sample_path = os.path.join(self.sample_dir, '{}-images.jpg'.format(i+1))
save_image(self.denorm(x_concat.data.cpu()), sample_path, nrow=1, padding=0)
print('Saved real and fake images into {}...'.format(sample_path))
# Save model checkpoints.
if (i+1) % self.model_save_step == 0:
G_path = os.path.join(self.model_save_dir, '{}-G.ckpt'.format(i+1))
D_path = os.path.join(self.model_save_dir, '{}-D.ckpt'.format(i+1))
torch.save(self.G.state_dict(), G_path)
torch.save(self.D.state_dict(), D_path)
print('Saved model checkpoints into {}...'.format(self.model_save_dir))
# Decay learning rates.
if (i+1) % self.lr_update_step == 0 and (i+1) > (self.num_iters - self.num_iters_decay):
g_lr -= (self.g_lr / float(self.num_iters_decay))
d_lr -= (self.d_lr / float(self.num_iters_decay))
self.update_lr(g_lr, d_lr)
print ('Decayed learning rates, g_lr: {}, d_lr: {}.'.format(g_lr, d_lr))
参考资料
PyTorch代码
StarGAN论文及代码理解
【论文阅读笔记】《StarGAN》
StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation


评论