
文本识别CRNN
CRNN
在传统的文本识别中,需要将检测到的文本行分割为单字符,再利用模板匹配或者图像分类识别单字符,这类方法处理过程较为繁琐,并且受限于字符分割的效果,左右结构的中文字符分割仍存在较多问题。在深度学习飞速发展的今天,端到端的文本识别,略去了字符分割步骤,将文本识别转化为序列识别,即将输入的文本行看作是文本序列,不需要严格要求输入文本行的长度统一。
CNN+RNN+CTC是目前最为流行的文本识别模型,其出处为https://arxiv.org/abs/1507.05717,通过CTC算法在转录时解决文本对齐问题。
网络结构
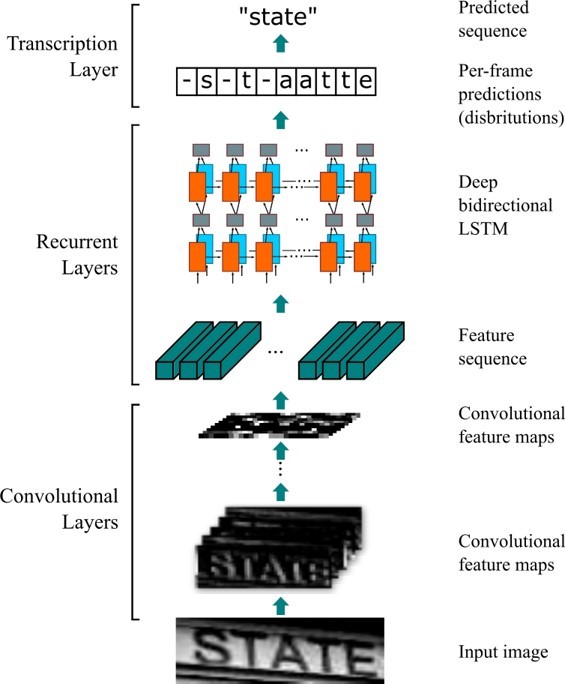
网络结构包含三个部分,卷积层、循环层和转录层:
- 卷积层:利用CNN提取输入图像的图像特征;
- 循环层:使用RNN提取序列的上下文语义信息;
- 转录层:使用CTC将RNN输出的序列预测概率整合为最后的输出结果。
卷积层
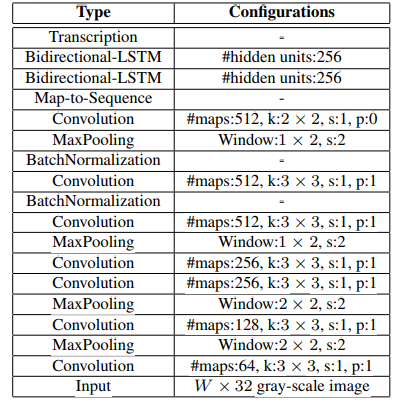
上图是论文中采用的网络参数,在输入时将图片统一为高度为32的灰度图。在结构中需要注意的是第三个和第四个pooling层采用的window大小为1*2,这样可以更好的区别i与I类似的字符。
这部分也可以采用VGG16,增加网络深度
循环层
采用循环层主要用于提取序列的上下文语义信息,具体可以参考:LSTM
转录层
CTC
RNN, Seq2Seq, Attention注意力
Github 相关项目
文本行合成
采用目标检测提取发票中的几项信息
chinese-ocr
chinese-ocr-lite
CTPN+DenseNet+CTC
ctpn+crnn+ctc
CRNN
reference:
- CRNN
https://zhuanlan.zhihu.com/p/43534801
https://www.jianshu.com/p/14141f8b94e5
https://www.cnblogs.com/skyfsm/p/10345305.html
https://www.cnblogs.com/skyfsm/p/10335717.html - VGG
https://www.cnblogs.com/lfri/p/10493408.html
https://www.sohu.com/a/241338315_787107
https://blog.csdn.net/amcle/article/details/79165348
评论

