

【CANN训练营第三季】数字视觉预处理
AI基础
用于图像视觉的编解码,将从网络或终端设备获取的视觉数据,进行预处理以实现格式和精度转换等要求,之后提供给AI计算引擎。
而在CANN中开发应用使用的DSL就是ACL(AscendCL),它提供了一套在昇腾平台上开发深度学习网络推理应用的C语言API库(Python为PyACL)。
ACL的基本功能分为两个方面,一个是运行资源管理,另一个为内存管理。运行资源管理可以指定硬件资源、创建管理对象和创建维护执行顺序的Stream;内存管理体现在各阶段申请数据的内存、释放内存和通过内存拷贝实现数据传输。
<img src=“/images/cann-intro3/2022-12-15-21-11-13.png” >
数据预处理
数据预处理是指当获取的源图或源视频不符合网络模型输入时,需要将源图或源视频处理为符合模型要求的图或视频。一般包括图或视频的编解码、色域转换、旋转缩放、剪裁等。
CANN提供了两套数据预处理方式:AIPP和DVPP。在使用时一般先使用DVPP对图片或视频进行解码、抠图、缩放等基本处理,再使用AIPP进一步做色域转换、抠图、填充等。
DVPP+AI ...
【CANN训练营第三季】【预备1】CANN背景
华为AI解决方案
2018年华为全连接大会上,华为发布了全栈全场景AI解决方案,包括Ascend、CANN、MindSpore、应用使能四个层次。其中,Ascend(昇腾)是基于统一、可扩展架构的系列化AI IP和芯片,包括Max、Mini、Lite、Tiny和Nano五个系列;CANN是芯片算子库和高度自动化算子开发工具;MindSpore为支持端、边、云独立的和协同的统一训练和推理框架;应用使能层可以提供全流程服务、分层API和预集成方案。
Ascend层(计算硬件)
Ascend即IP和芯片组层,目标是在任何场景下以最低成本提供最佳性能。Ascend使用统一架构,只需要进行一次算子开发,然后便可以在任何场景下使用;跨场景一致的开发和调试体验;在某个芯片上完成算法开发可以顺利地迁移到面向其他场景的IP和芯片上。
CANN层(异构计算架构)
偏底层、偏通用的计算框架,用于针对上层AI框架的调用进行加速,提供芯片算子库和算子开发工具包,目标是兼具最优开发效率和算子性能,以应对学术研究和行业应用的蓬勃发展。
MindSpore(AI框架)
MindSpore是统一的训练/推 ...

排序算法
十大经典排序算法
排序算法
平均时间复杂度
最好
最坏
空间复杂度
稳定性
冒泡
O(n2)O(n^2)O(n2)
O(n)O(n)O(n)
O(n2)O(n^2)O(n2)
O(1)O(1)O(1)
稳定
快排
O(nlog(n))O(nlog(n))O(nlog(n))
O(nlog(n))O(nlog(n))O(nlog(n))
O(n2)O(n^2)O(n2)
O(log(n))O(log(n))O(log(n))
不稳定
归并
O(nlog(n))O(nlog(n))O(nlog(n))
O(nlog(n))O(nlog(n))O(nlog(n))
O(nlog(n))O(nlog(n))O(nlog(n))
O(n)O(n)O(n)
稳定
冒泡算法
12345678910template<typename T>void bubbleSort(T arr[], int len){ for(int i = 0; i < len; i++){ for(int j=1; j < len - ...
深度学习基础
网络基础
卷积层参数量
普通卷积
卷积参数: kw∗kh∗Cin∗Cout+Coutk_w *k_h*C_{in}*C_{out}+C_{out}kw∗kh∗Cin∗Cout+Cout (加偏置)
输出图像大小:⌈Cout=Cin+2∗padding−kernelstride+1⌉\lceil C_{out} = \frac{C_{in}+2*padding-kernel}{stride} +1 \rceil⌈Cout=strideCin+2∗padding−kernel+1⌉
乘法次数:kernel∗kernel∗Cin∗Cout∗Wout∗Houtkernel*kernel*C_{in}*C_{out}*W_{out}*H_{out}kernel∗kernel∗Cin∗Cout∗Wout∗Hout (输出图的每个像素点计算)
深度可分离卷积
卷积参数: (kw∗kh∗1+1)∗Cin+(1∗1∗Cin+1)∗Cout(k_w *k_h*1+1)*C_{in}+(1*1*C_{in}+1)*C_{out}(kw∗kh∗1+1)∗Cin+(1∗ ...
机器学习基础
L1和L2正则化
正则化是机器学习中对原始损失函数引入额外信息,以防止过拟合和提高模型泛化性能。正则化后目标函数变为 原始目标函数 + 正则化项,一般有两种,L1正则化和L2正则化,或者L1范数和L2范数。采用L1正则化的模型叫做Lasso回归,使用L2正则化的模型叫做Ridge回归(岭回归)。
L1正则化是指权值向量中各个元素的绝对值之和,通常表示为∣∣ω∣∣1||\omega||_1∣∣ω∣∣1
L2正则化是指权值向量中各个元素的平方和再求平方根,通常表示为∣∣ω∣∣22||\omega||_2^2∣∣ω∣∣22
L1正则化可以使得参数稀疏化,即得到的参数是一个稀疏矩阵,可以用于特征选择。
L2正则化可以防止模型过拟合,L1也可以。
L2计算起来更方便,而L1在非稀疏向量上的计算效率很低;L1输出稀疏,会把不重要的特征值直接置零;L2有唯一解。
L1范数符合拉普拉斯分布,是不完全可微的,最优值出现在坐标轴上,产生稀疏权重矩阵,进而防止过拟合;L2范数符合高斯分布,是完全可微的,一般最优值不会出现在坐标轴上,最小化正则项时,参数不断趋于0,最后获得很小的参数。
降低过拟合 ...
DL-优化器
指数加权平均与偏差修正
指数加权平均
指数加权平均也叫指数加权移动平均,是一种常见的序列数据处理方式,计算公式如下:
at=βat−1+(1−β)bta_t = \beta a_{t-1} + (1-\beta) b_t
at=βat−1+(1−β)bt
在上式中,
btb_tbt表示第t天的观测值;
ata_tat是要代替btb_tbt的估计值,也就是第t天的指数加权平均值;
β\betaβ表示at−1a_{t-1}at−1的权重,是可调节的超参。
简单来说,就是用ata_tat作为btb_tbt的估计值,这种方法可以抚平短期波动,起到平滑的作用。
为什么叫做指数加权平均?
若将at,a_t,at,展开,可以得到下式:
at=(1−β)bt+(1−β)∗βbt−1+(1−β)∗β2bt−2+⋯+(1−β)∗βt−1b1a_t = (1-\beta)b_t + (1-\beta)*\beta b_{t-1} + (1-\beta)*\beta^2 b_{t-2} + \dots + (1-\beta)*\beta^{t-1} b_{1}
at=(1−β) ...
cpp-操作效率
数据结构操作效率
数据结构
查找
插入
删除
遍历
数组
O(N)
O(1)
O(N)
—
有序数组
O(logN)
O(N)
O(N)
O(N)
链表
O(N)
O(1)
O(N)
—
有序链表
O(N)
O(N)
O(N)
O(N)
二叉树(一般情况)
O(logN)
O(logN)
O(logN)
O(N)
二叉树(最坏情况)
O(N)
O(N)
O(N)
O(N)
平衡树(一般情况和最坏情况)
O(logN)
O(logN)
O(logN)
O(N)
哈希表
O(1)
O(1)
O(1)
—
栈
—
O(1)
O(1)
—
队列
—
O(1)
O(1)
—
优先队列(堆)
—
O(logN)
O(logN)
—
上表源自:常用数据结构各个常用操作的性能对比
数组与链表的性能分析
插入/删除(时间复杂度)
查询(时间复杂度)
数组
O(n)
O(1)
链表
O(1)
O(n)
哈希结构
集合
底层实现
是否有序
数值是否可以重复
十分可以更改数值
查询效率
增删效率
set
红黑树 ...
cpp-基本数据结构
数组
基本数组的定义及初始化
对于CPP基本数据的定义以及初始化
123456789type arrName[count] = {val1, val2, val3, ...};// 定义int a[10];char x[2];// 初始化for (int i = 0; i<10; i++){ a[i] = i;}
初始化也可以采用枚举方法
12int x[2]={2,3};int x = {4,5,6};
根据大括号里面的个数初始化原数组,当个数不匹配时初始化前面的元素,其后为0。
对于char类型的数组,可以用memset初始化
1234#include<cstring>char x[2];memset(x,'a',2);
而对于int或double不适用,这是由于memset是按字节赋值,char数组每个元素为一个字节,而int占用四个字节。可以设置0或-1
1234int x[6];memset(x,0,sizeof(x));memset(x,-1,size ...
损失函数
损失函数是代价函数的一部分,而代价函数是目标函数的一种类型
Loss function,即损失函数:用于定义单个训练样本与真实值之间的误差;
Cost function,即代价函数:用于定义单个批次/整个训练集样本与真实值之间的误差;
Objective function,即目标函数:泛指任意可以被优化的函数。
损失函数可以分为三类:回归损失函数、分类损失函数和排序损失函数。
L1 Loss
平均绝对误差(Mean Absolute Error, MAE),它衡量的是预测值与真实值之间距离的平均误差幅度,作用范围为0到正无穷。
优点:对离群点或者异常值更具有鲁棒性。
缺点:在0处导数不连续,求解效率低,收敛速度慢;对于所有的损失值,梯度一样,不利于网络学习。
L2 Loss
均方差(Mean Squred Error, MSE),它衡量的是预测值与真实值之间距离平方和的均值,作用范围同为0到正无穷。
优点:收敛速度快,能够对梯度给予合适的惩罚权重,而不是“一视同仁”,使梯度更新的方向可以更加精确。
缺点:对异常值十分敏感,梯度更新的方向很容易受离群点所主导,不具备鲁棒性。
Smoo ...
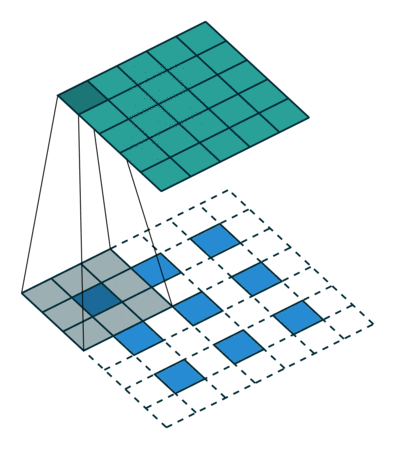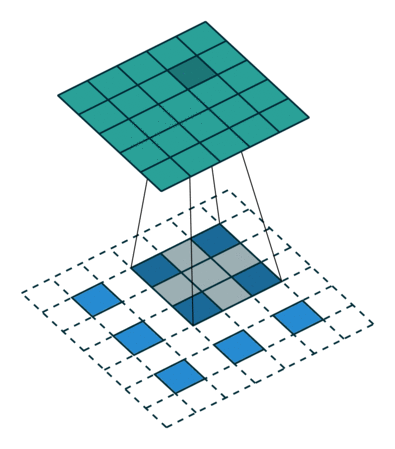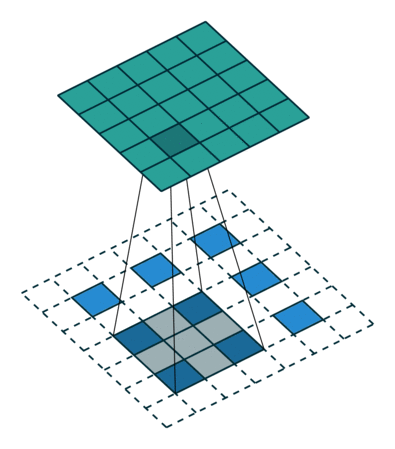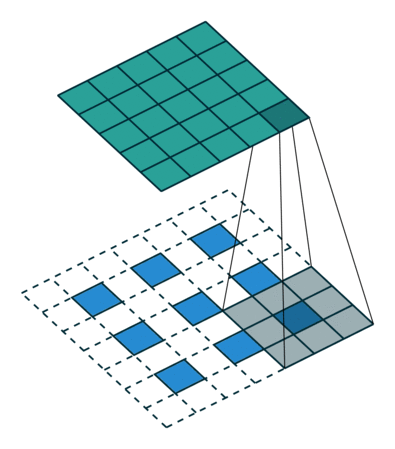
各种卷积层
卷积可以捕获图像相邻像素的依赖性,起到类似滤波器的作用,得到不同形态的特征图。
普通卷积
1D卷积
1D卷积主要应用于时序数据,上图所示的数据有三个数据点,卷积核沿着时间维度滑动。适用于音频和文本数据。
1class torch.nn.Conv1d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
in_channels(int) – 输入信号的通道。
out_channels(int) – 卷积产生的通道。有多少个out_channels,就需要多少个1维卷积
kernel_size(int or tuple) - 卷积核的尺寸,卷积核的大小为(k,),第二个维度是由in_channels来决定的,所以实际上卷积大小为kernel_size*in_channels
stride(int or tuple, optional) - 卷积步长
padding (int or tuple, optional)- 输入的每一条边补充0的层数
dilat ...
