

BN IN LN GN
归一化层
Batch Normalization (2015)
Layer Normalization (2016)
Instance Normalization (2017)
Group Normalization (2018)
BN是在batch上,对N、H、W做归一化,而保留C的维度,即在每个通道上计算一个batch的均值与方差;
LN是在通道方向上,对C、H、W做归一化,即对每一层计算均值与方差与batch无关;
IN是在单个特征图上,对H、W做归一化,即对每个输入实例的每个特征图计算均值与方差;
GN是将通道分组,再做归一化。
对于BN、IN与GN,可学习参数γ\gammaγ和β\betaβ的维度都是通道数。
BN对小batchsize效果不好;
LN对RNN作用明显,(与batch无关,在深度上做归一化);
IN主要用于风格化迁移;
GN是针对BN在batci size较小时错误率较高而提出的改进算法
Batch Normalization
为什么要进行BN?
在深度神经网络训练的过程中,通常以输入网络的每一个mini-batch进行训练,这样每个batch ...
目标检测
one stage、two stage、anchor-based、anchor-free
这四者是从两个并行的维度划分;单、双阶段划分依据是是否存在显示的ROI特征提取过程,如Faster RCNN中RPN模块负责提取ROI,再输入到RCNN中进行识别和定位,而单阶段没有显式ROI提取过程,如YOLO。
anchor-based与anchor-free划分依据是是否需要显式定义先验anchor,如Faster RCNN、YOLOv2等主流算法都需要定义先验框的尺寸,YOLOv1、DenseNet是anchor-free的。
one stage方法就是在特征图的每个位置上,使用不同尺度、长宽比密集采样生成anchor,直接进行分类和回归。主要优点是计算效率高,但检测精度稍差(主要是没有删除负样本的anchor,导致类别不均衡,RetinaNet采用focal loss),对小物体检测效果差(two stage中的roi polling对目标做resize,小目标的特征被放大,其轮廓也更为清晰,解决方法最简单的是增大输入尺寸,但会丧失速度快的优势,还可以采用FPN融合底层特征、空洞卷积增加 ...

Python程序执行过程
解释型语言和编译型语言
CPU 只能直接执行机器语言,所以需要将高级语言转为机器语言,这个过程分为两种,一种是编译,一种是解释。
编译型语言是在程序执行之前,通过编译器对程序源代码进行编译,转为机器语言,直接运行,最具代表的就是 C 语言。
解释型语言是指在程序执行的时候,通过解释器对程序逐行做出解释,直接运行,不需要提前编译,最具代表的是 Ruby。
随着技术的发展,也出现了不同于以上两种的语言类型。C#在编译时生成中间码,在.NET 平台上运行。Java 首先通过编译器生成字节码文件,在运行时通过解释器解释为机器语言。
Ps:动态语言和静态语言是指程序运行时是否能够改变改变程序的结构,与解释、编译型语言无关。Java 是解释型语言但不是动态语言。
PPs:动态类型语言和静态类型语言是指语言的数据类型是在哪个过程确定的。动态类型语言在运行期间确定数据类型;静态类型语言的数据类型是运行前确定是
PPPs:强类型语言和弱类型语言。强类型语言是指变量的数据类型不经过强制转换不能改变;弱类型语言的一个变量可以赋不同数据类型数值
编译器与解释器
编译器与解释器都 ...
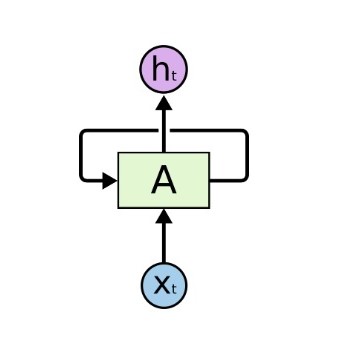
循环神经网络
RNN
增加了上一个时间步的隐藏状态H(t−1)H_{(t-1)}H(t−1)
Ht=f(XWxh+Ht−1Whh+bh)H_t = f(XW_{xh}+H_{t-1}W_{hh}+b_h)
Ht=f(XWxh+Ht−1Whh+bh)
Ot=HtWhc+bcO_t = H_tW_{hc}+b_c
Ot=HtWhc+bc
缺陷:
梯度消失与梯度爆炸;
长期依赖的问题
循环神经网络 (Recurrent Neural Network, RNN)
LSTM
增加了输入门、遗忘门和输出门,同时包含隐藏状态的记忆细胞,这种门结构使其具有向单元状态增加或删除信息的能力。输入为记忆细胞Ct−1C_{t-1}Ct−1、隐藏状态Ht−1H_{t-1}Ht−1和输入XtX_tXt。
遗忘门:决定从上一时刻记忆细胞中遗忘的信息。Ft=σ(XtWxf+Ht−1Whf+bf)F_t = \sigma(X_tW_{xf}+H_{t-1}W_{hf}+b_f)Ft=σ(XtWxf+Ht−1Whf+bf)
输入门:决定记忆细胞中储存什么新信息。It=σ(XtWxi+H ...
标签分布学习
背景
学习的本质是构建从实例到标签的映射关系,但有时候标签存在模糊性,即一个实例不一定映射到一个标签,现有的学习范式中,主要存在两种形式——单标签学习和多标签学习。单标签学习是指给一个实例分配一个标签,多标签学习是指给一个实例分配多个标签。
以上两种形式都在回答一个问题:“哪个(哪些)标签可以描述这个实例”,但都没有回答一个问题是“每个标签能够在多大程度上描述这个实例”,也就是每个标签之间相对的重要程度。
假设对于一个实例 xxx,分配一个实数 dxyd_x^ydxy 描述yyy描述xxx的程度。一般dxy∈[0,1]d^y_x \in [0,1]dxy∈[0,1],如果这个标签集是完整的,标签集合里面的标签总是能够完整的描述实例,则存在 ∑ydxy=1\sum_y{d_x^y}=1∑ydxy=1.
对于一个实例,所有标签的描述程度构成一个类似于概率分布的数据形式,称为标签分布。
与传统学习范式
每个LDL实例都与标签分布明确相关,而不是单个标签或相关标签集,标签分布的标签来自于原始数据,是原始数据的一部分,而不是人为地从原始数据生成的。
以前的学习范式通过对预测结果 ...

Git-Cheat-Sheet
Git Cheat Sheet 中文版
索引
配置
配置文件
创建
本地修改
搜索
提交历史
分支与标签
更新与发布
合并与重置
撤销
Git Flow
配置
列出当前配置:
1$ git config --list
列出 repository 配置:
1$ git config --local --list
列出全局配置:
1$ git config --global --list
列出系统配置:
1$ git config --system --list
设置用户名:
1$ git config --global user.name “[firstname lastname]”
设置用户邮箱:
1$ git config --global user.email “[valid-email]”
设置 git 命令输出为彩色:
1$ git config --global color.ui auto
设置 git 使用的文本编辑器设:
1$ git config --global core.editor vi
配置文件
Repository 配置对应的配置文件路径[–local ...
Git Commit message规范
引文
每一次用git commit 都要填写 message,自己之前的提交都比较随意,每次提交的格式也都不仅一样,寻找起来也比较困难。
Commit message 的作用
提供直观明了的历史信息,方便浏览,利用--pretty=oneline可以再一行内确定提交的信息
可以过滤某些 commit,便于查找
利用git log HEAD --grep feature可以仅查看发布的新功能
由 commit 直接生成 Change log
规范
目前使用比较广泛的为 Angular,每次提交都包括三部分:Header,Body 和 Footer。
12345<type>(<scope>):<subject><body><footre>
Header(可选)
Header 部分只有一行,包括三个字段:type(必需)、scope(可选)和 subject(必需)
type
type用于说明 commit 的类别,只允许使用下面 7 个标识。
12345671. feat:新功能(feature)1. fix: ...
Git
基本用法
Reference https://www.liaoxuefeng.com/
配置
Git 一共分为三个级别的配置 system、global、local,分别是系统级、用户级、当前仓库
1234# 查看配置文件git config --system --listgit config --global --listgit config --local --list
在 global 中需要配置提交的用户名和 Email 地址,
这是由于 Git 是分布式版本控制系统,在提交的时候需要自报家门。
1234# 配置用户名git config --global user.name "Your name"# 配置Email地址git config --global user.email "email@example.com"
上述是对本机上所有的仓库进行了配置,也可以单独对某个仓库进行配置。
创建版本库 (repository)
1git init
将当前目录变成 Git 可以管理的仓库,(为了避免出现错误,目录中不要出现中文)
创建版本库之后 ...
python-面向过程
关于编码
ASCII & Unicode & UTF-8 文件在内存中使用 Unicode,在硬盘或者需要传输的时候自动转为 UTF-8。Python 中字符串类型是str可以使用b''转为以字节为单位的bytes,如:x=b’abc’。以 Unicode 表示的str通过encode()方法可以编码为指定的bytes,如’abc’.encode(‘ASCII’)
关于格式化
输出格式化的字符串,可以与 C 语言一样使用%,也可以使用format(),如’Hi,this is %s’%(‘Jim’),‘Hi,this is {0}’.format(‘Jim’)
关于数据类型
Python 中内置的数据类型包括数值类型、序列对象和键值对。
数值类型
int 整形
float 浮点型
complex 复数
bool 布尔值
序列对象
str 字符串
list 列表
tuple 元组
键值对
set 集合
dict 字典
字符串使用[]定义,其值是可以改变的,也可以使用索引、切边;追加元素到末尾append();插入到指定位置insert() ...
Python-TIPS
for .... else 循环
for 循环能正常结束,则运行 else;如果是 break 结束,则不运行 else
__dict__
__dict__中存储了对象的属性,类和实例都有自己的属性,内置对象没有属性。
类对象的__dict__中存储了类的静态函数、类函数、普通函数、全局变量以及一些内置属性
实例对象的__dict__中存储一些self.xxx的一些东西
try...except...else...finally
123456789101112131415161718192021222324try: 可能发生异常的代码except: 如果出现异常执行的代码else: 没有异常执行的代码finally: 无论是否有异常都要执行的代码 # 带as except 异常类名 as result : print(result) # 异常描述信息 # 自定义异常,继承于Exception class 异常类名(Exception): def __init__(self): def __str__(self): ...
